AMIを駆使したリリースバージョン管理の仕組み
お久しぶりです。
以前こちらの記事を書かせていただきました、Cメディア開発グループの伊藤です。
今回は、「不動産情報サイト アットホーム」のリリース運用について紹介できればと思います。
新しいプロジェクトの開発において、リリース作業は必要不可欠ですよね? 多くのユーザーが快適に不動産情報サイト アットホームを利用できるように、常に最新の情報や使いやすい機能を提供することが求められます。 そのためには定期的なバージョン更新が必要です。
また、本番環境のリリースが行われれば、それに合わせて複数ある検証環境も随時更新していかないと環境自体がどんどん古くなってしまいます。 基盤チームで環境を管理している私たちにとって、特に検証環境の多さやバージョン管理の必要性は日々痛感するところです。
そこで今回は不動産情報サイト アットホームをリリースする際のバージョン管理の仕組みに焦点を当て、AWSサービスを駆使した環境管理の舞台裏を覗きつつ、運用していて私が実際に感じていることを率直にお話していきたいと思います。
前回に引き続き、AWSやエンジニアの世界に興味を持ってもらえるような記事となればうれしいです。
目次
不動産情報サイト アットホーム リリースの仕組みは?
では、早速ですが不動産情報サイト アットホームのリリースはどのように行われているのでしょうか?
不動産情報サイト アットホームのリリースは、Blue/Greenデプロイツール(以下、BGツール)と呼ばれる処理が走ることで、APサーバ、WEBサーバ、検索用DBサーバの構築を一元的に行っています。 この方法を確立する前は稼働中のサーバのファイルを手動でアップデートしていたため、リリース作業が大変手間だったと当時運用していた方からも聞いています。
ここでは新しい環境が構築されるまでの流れを視覚的にイメージしやすいように紹介します。
前提として「Blue面」(=稼働中の環境)と「Green面」(=新しく構築する環境)、この2つがリリースの”セット”だと考えていただければと思います。
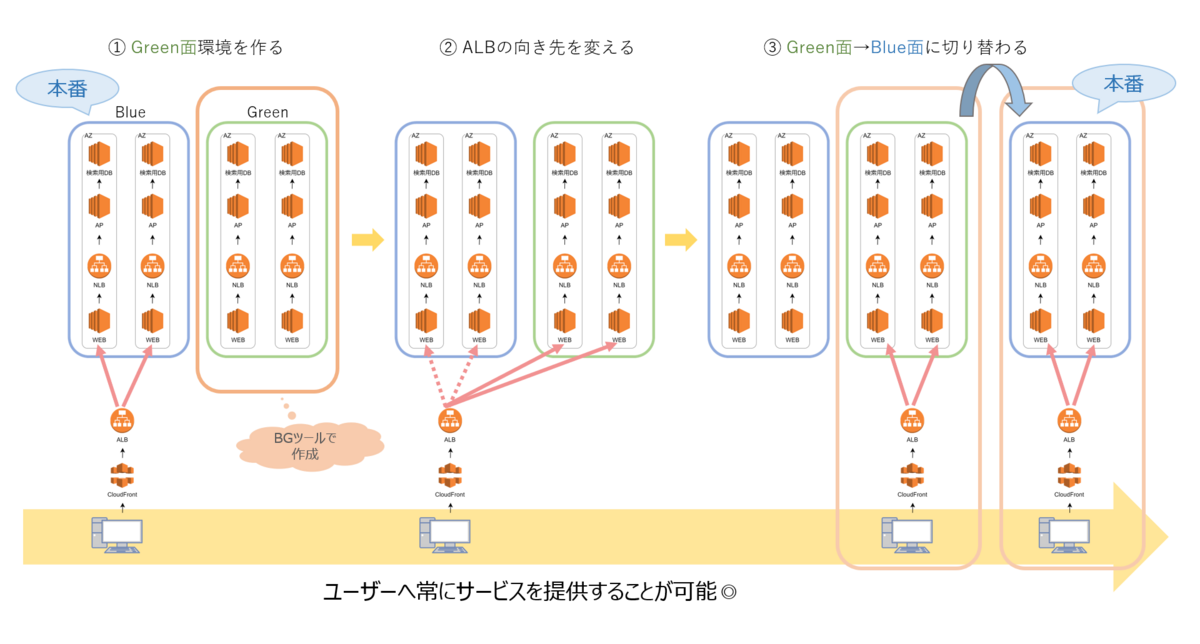
新しい環境が構築されるまでの手順
①BGツールが動くと、「Green面」環境が新たに作られる
②必要なリソースが問題なく作成されたらALB*1の向き先を切り替える
③切り替えがうまくいったら、BGツールで作成した「Green面」環境が「Blue面」環境として稼働する
※不要になった旧「Blue面」は、問題なく新しい環境に切り替わったことを確認した後、削除される
次のリリースが行われる場合は①~③をまた繰り返します。
もし構築に失敗した場合は新しい環境には切り替えず前バージョンのサーバで稼働し続けるため、サイトが見られなくなるというようなトラブルを防ぐことができます。
このような運用方式にすることで、ユーザーにサービスを提供しながら新しい環境の構築が可能となり、安定した稼働が実現できているのです。
では、BGツールは何の情報を基にインスタンスを作成しているのでしょうか。
その答えが今回ご紹介する「AMI」となります!
AMIって何?
では、AMIとはいったい何なのでしょうか?
AMI(Amazon Machine Image)とは、Amazon EC2(Elastic Compute Cloud)インスタンス(=実際に動く状態になったサーバ)を作るためのテンプレートであり、
いわばインスタンスの「ひな形」のようなものです。
このAMIを使用することでサーバに必要なOSやデータが組み込まれた新しいEC2インスタンスを手軽に作成でき、簡単に運用を始めることができます。
“手軽にインスタンスを作成するためのAMI”というイメージですが、実はほかの活用方法もあるのです。
AMIには4つ種類があるので、今回は1つずつ身近なものに例えながら紹介していきます。

一言でAMIと言ってもさまざまな使い道がある中で、不動産情報サイト アットホームでは「カスタムAMI」を活用してサーバを再構築しています!
AMIを使ったバージョン管理
では、先程触れた「カスタムAMI」を実際にどのようにバージョン管理に利用しているのでしょうか?
今回は実際に私が運用している不動産情報サイト アットホームの検証環境を例に紹介します。
検証環境では、1日に何度も自動的にリリースが走ったり開発者が手動でもリリースできたり…と実際はなかなかの頻度でリリースが行われています。
そのため、より頻繁なビルド/デプロイでも環境が維持できるようなバージョンの管理体制が必要不可欠なのです。
AMIを作成、利用するタイミング
AMIは各サーバごとに作成され、そして作成を行うとAMIIDといわれる「ami-」から始まるランダムな英数字で構成されたIDを発行します。
そのAMIIDをインスタンス作成時に指定することで、そのバージョンのインスタンスが作成されるという仕組みとなっています。
以下は検証環境でAMIが作成されるタイミングと、AMIIDを使ってインスタンスを作成する(=リリースされる)タイミングを図で表したものです。
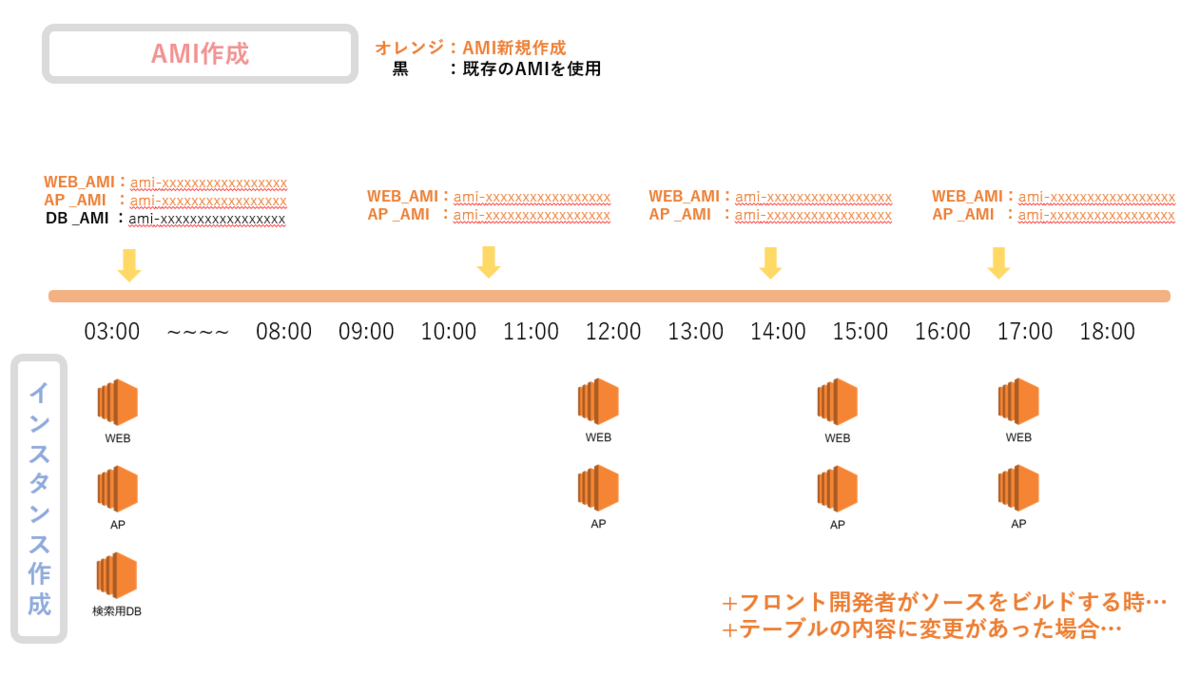
ここまで検証環境で頻繁にリリースが行われているのは、開発者が日々多くの案件に対応する中で、開発の修正をより早く頻繁に画面反映させるようにするためです。
検索用DBのバージョン管理
検索用DBはテーブルの内容に変更があった場合のみ、AMIの作成が行われます。
これは不動産情報サイト アットホームには連携用DBと検索用DB、2種類のDBが存在することが理由として挙げられます。
サイト上に物件データを表示させるためには、連携用DBから検索用DBサーバにデータをロードする必要があります。
ただし、この連携用DBと検索用DBのテーブルの設定を正確に合わせないと、サイト自体が正しく動作しなくなってしまいます。
どの変更を含んだバージョンを基にDBを作成するのか、そのテンプレート的な役割を担っているのもAMIなのです。
※検索用DBサーバのインスタンス作成のタイミングは
①テーブルの内容に変更があった場合(AMI作成時)
②夜間データ洗替時
のみとなっています。
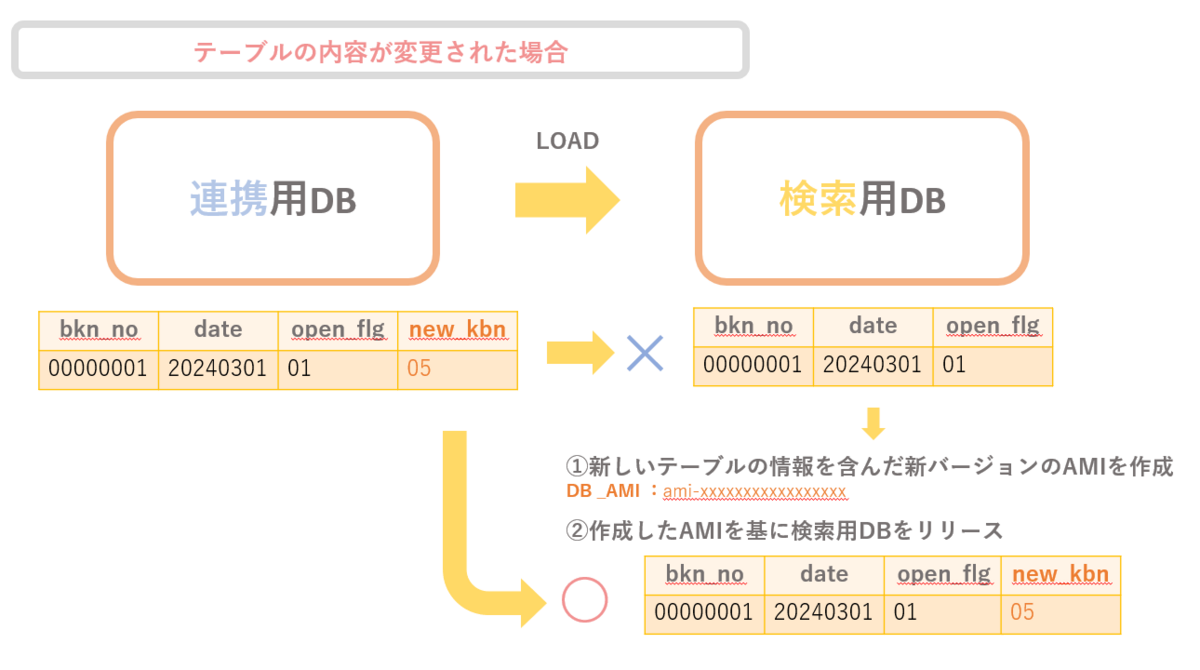
図4の様に、「bkn_no(物件No)」「date(登録日付)」「open_flg(公開フラグ)」のカラム情報を持っているテーブルがあるとします。
このテーブルに新しいカラム「new_kbn(新区分値)」を追加したい場合、連携用DBだけに登録してしまうと検索用DBへのロード時に整合性が合わずエラーとなってしまいます。
それを防ぐためにAMIを用いて整合性を持たせます。
①新しいテーブルの情報を含んだ新バージョンのAMIを作成
②作成したAMIを基に検索用DBをリリース
検索用DBのリリース後に連携用DBのカラム情報を登録することで、検索用DBへのロード時にエラーになるトラブルを防ぐことができます。
また検索用DBからリリースを行うことで、万が一検索用DBにだけ新しいカラムがある状態で連携が走ってしまっても、新しいカラムの値はNULLとして登録されるだけなのでサービスに影響はありません。
このように検証環境では頻繁なAMI作成が行われていますが、実はAMIの作成が行われるのは検証環境だけなのです。
その理由が、不動産情報サイト アットホームがAMIを用いてリリース管理を行っている最大の要因になります。
環境構築からリリースまで
では、その最大の理由を紐解くためにまずは実際に新しいプロジェクトの環境構築からリリースに至るまでのフローを追ってみましょう。

①今回のプロジェクトで利用する環境に対して、構築作業を行う
検証環境は現在全部で10面前後あります。その中から今回のプロジェクトで使用する環境を管理者が決め、基盤を最新のバージョンに合わせる作業(=構築作業)をしていきます。
この時構築した基盤と同じバージョンのDB_AMIIDを指定することで、連携用DBとの整合性を担保しています。
②フロントのリリースバージョンをその環境にあてる
基盤の構築完了後、フロント側のバージョンを環境に指定することで、開発期間中は常に特定のリリースブランチでAMI作成からリリースまでを行うことができます。
③作成された環境で、開発→テストを行う
開発中、検証環境では頻繁にリリースが行われます。
そして開発チームが検証環境にリリースしたものをテストチームが確認していきます。
④テスト完了後、AMI凍結を行う
テストが終わると、リリース対象の検証環境のブランチがこれ以降勝手に更新されないように設定を行います。
この、テスト完了後にリリースブランチのアップデートを止める作業を私たちは「AMI凍結」と呼んでいます。
「AMI凍結時点のAMIID」を本番に設定しリリースを行うことで、テストチームがテストした完璧なリソースのみをリリースできるような仕組みになっています。
⑤リリース作業を行う
④で凍結したAMIIDを基にリリースが行われ、開発した機能やサービスがユーザーに提供されます。
もうお気づきの方もいるかと思いますが、環境構築からリリースまでの手順で出てきた「AMI凍結」が今回のカギになります。
「テストを完全に終わらせた完璧なブランチでしかAMIを作成しない」というフローを確立することで、ブランチのコミット漏れや余分なコミットから引き起こされるサービス障害のリスクを防いでいるのです。
これがAMIを用いてリリースバージョンを管理している最大の理由となります!
また、他にも、サーバのオートスケーリング*2を実現するためにもAMIは欠かせないものとなっています。
実際の運用で感じた効果や課題
AMIをつかったバージョン管理の仕組みとメリットが整理できたところで、私が実際に基盤チームで環境を管理していて感じていることをお話ししていきたいと思います。
やはり一番は、リリースの手軽さやリリースのしやすさなのではないかなと思います。
AMIの作成、BGツールの実行、新しいバージョンのリリースまでが簡単に30分ほどで完了すること、そして作成で失敗した場合は切り替わらないという仕組み自体がリスクを最小限に抑えられているため、開発や運用がスムーズだと日々感じています。
特にAPサーバやWEBサーバに関しては、毎回リリースされるたびにAMIIDが作成されるため、本番環境へリリースする際のバージョンの信頼性が確保されていて安心感があります。
また、検証環境の構築作業で基盤を最新の状態まで更新させたい時、AMIは環境依存をしていないので一度別の環境で作成したAMIを他の環境にも使用することができます。
最新のAMI_IDを指定することで最新化した連携用DBとの整合性を保った検索用DBが簡単に作成できることも、便利だと感じているところです。
構築作業は1カ月に2~3度は発生する作業なので、手間をかけずに作業できるのはとても心強い仕組みです。
検証環境を運用していて私が課題と感じる点は、検索用DBのAMI管理でどのAMIがどの環境で使われているのかを逐一チームで把握していないと連携用DBと検索用DBの整合性がとれずエラーになってしまった場合に、原因の特定やどのバージョンのAMIと整合性が合うのか特定するのに時間が掛かってしまうことです。
現在は社内ツールのドキュメントで管理しているためそちらを参考にすれば問題はありませんが、記載漏れも可能性としては大いにあるので、より確実な運用の確立が必要かもしれません。
ここまで不動産情報サイト アットホームのリリース管理について整理してきましたが、私は一つの疑問が浮かんでいました。
AWS勉強中の私にとっては、「ビルド→デプロイを素早く安全に実現できるサービスは?」といわれると、まずCodePipelineをはじめとしたCodeシリーズ*3を考えます。
Codeシリーズを採用せずにAMIでの管理に踏み切った理由ってなんだろうと疑問に思ったので、これを機に有識者の方に伺ってみました!
Codeシリーズは毎回コンテナを立ち上げ直してデプロイが行われるので、いくら環境を同じにしたつもりでも環境依存のリソースが足りないなどでコンテナを立ち上げ直した際にエラーが出てしまう可能性があります。
対してAMIの場合、必ずベースのAMI(OSとミドルウェアのみが入ったAMI)から作成しているので、必要なミドルウェアが不足している・・・などのトラブルでエラーになる心配もなく、スムーズにインスタンスを作ることができます!
とのことでした。
また、Codeシリーズを全く使用していないというわけではなく、一部のサービスではCodeシリーズをベースにAMIを現行のBGツールと同じ思想でリリースを行っているということでした。
AMIでの運用方式を取り入れることで必要な部品がそろった前提でインスタンス作成することができ、単にCodeシリーズのみで構築するよりも安全な運用設計になっているのだという工夫に気づくことができました。
「CI/CDに強いサービスはCodeシリーズで、これさえ使えば問題ない。」という単純な設計ではなく、
実現したい状況に応じて何のサービスを使うべきかが細かく選定され、運用面にも考慮された最適な設計なのだと再認識することができました!
まとめ
今回のテーマ選定の目的は、AMIを駆使したバージョン管理の仕組みをより深く理解していただくこと、そしてAMI自体について幅広く知っていただきたいという思いからでした。
自分自身、これまで検証環境の運用に取り組んでいましたが理解が曖昧な部分も多くありました。
しかし今回の執筆を通じて改めて仕組みを整理し直すことで点と点が線でつながる感覚が生まれ、不動産情報サイト アットホームの運用プロセスについての理解を一層深めることができました。
運用のしやすさも再認識し、自身の成長を感じています。
またAMIを使ったバージョン管理のしくみや、運用上のメリットにも改めて目を向けたことでの学びもありました。
AMIの活用方法に関しては単純に「簡単にインスタンス作成ができるもの」だと理解していましたが、その実態をより深く知ることでサービスの潜在的な活用の幅に気づくことができたと思います。
それぞれのサービスや運用にあったベストプラクティスが考えられるよう、今後もAWSサービスごとの知識を深めていきたいです。
最後までお読みいただきありがとうございました!
紙とWebのデザイン:知っておきたい共通点と相違点
お久しぶりです。WEBデザイングループの森田です。
以前、こちらのブログを書かせていただきました。
今回もデザイナーという仕事に興味を持っていただけるよう、お話ししていきたいと思います。
デザイナーと一口に言っても、紙などの印刷物をデザインするグラフィックデザイナー、WebサイトをデザインするWebデザイナー、そしてデザイン制作スケジュールや品質を管理するアートディレクターなど、デザインに関わる職業はたくさんあります。
デザインに関わる職業に就くためには、何に力を入れて技術を習得すればよいのか、また、一つに絞らなければならないのかと悩む方もいるかもしれません。
そこで、今回は大学で紙デザイン(グラフィックデザイン)を学び、入社後にWebデザインを扱うようになった私の実体験をもとに、紙とWebのデザインの違いについてまとめていきたいと思います。
目次
紙とWebのデザインの流れ
まずは、紙とWebのデザイン作業の流れを見ていきましょう。
例として、紙ではイベントのポスター、Webではイベントのランディングページ(イベント情報がまとまった単体のページ)をデザインする場合を考えます。
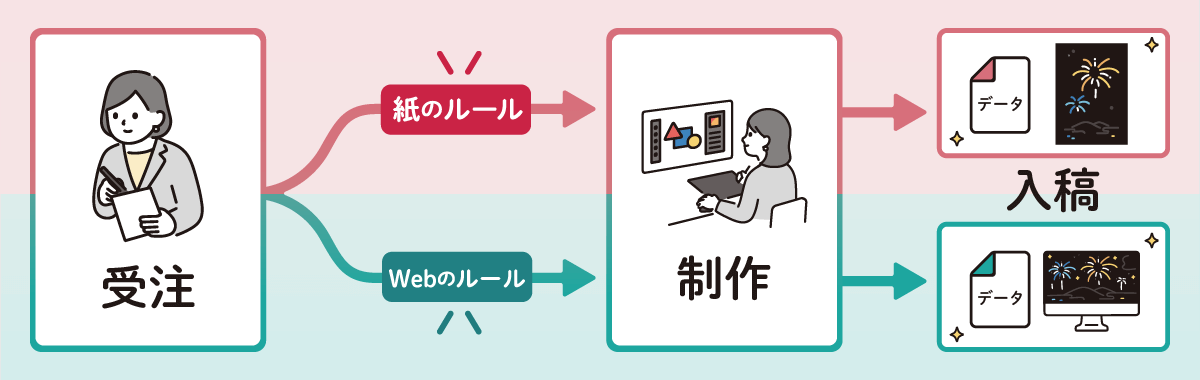
図のように紙とWeb、それぞれ受注・制作・納品という全体の流れは同じです。
STEP1 受注
まず最初に、クライアントなどから作成してほしいものを受注します。
その際には、目的や要望をしっかりとヒアリングしていきます。
ヒアリングが不足していると、後工程での手戻りや齟齬が生じることがあるため、この工程は非常に重要です。
ヒアリングが完了したら、デザインの表現方法や情報の優先順位など、制作につなげるための準備を進めていきます。
STEP2 制作
情報の整理ができたら、制作に移ります。
入稿の形態に合わせて、Adobe Illustrator・Adobe Photoshop・Adobe XD・Figmaなどのアプリケーションを用いてデータを作成していきます。
制作が終わったら、初校データを作成し、クライアントに修正点などを確認してもらいます。
会社によっては、この段階で校正や校閲も行い、出版物としての品質を向上させていきます。
STEP3 入稿
最後にデザインデータを出力するための工程へと入稿していきます。
紙の方では印刷をする必要があるので、印刷所のガイドラインなどに沿って制作データから入稿データを書き出していきます。
Webの方ではデザインをサイトに表示する必要があるので、サイト表示の作業をする方にデザインデータを入稿します。
このように、紙とWebのデザイン作業の流れは大まかには同じですが、受注と制作の間には「各媒体のルール」が存在します。
これらのルールが、紙とWebの共通点および相違点として表れるのです。
紙とWebのデザインの共通点
紙とWebのデザインの共通点は「情報の見やすさ・整理」です。
どちらの媒体でも、クライアントが伝えたい情報が視覚的に理解しやすいように、デザイン4原則や配色技法を駆使して表現する必要があります。
以下では、デザイナーが必ず学ぶべき「デザイン4原則」を紹介します。
【デザイン4原則】近接
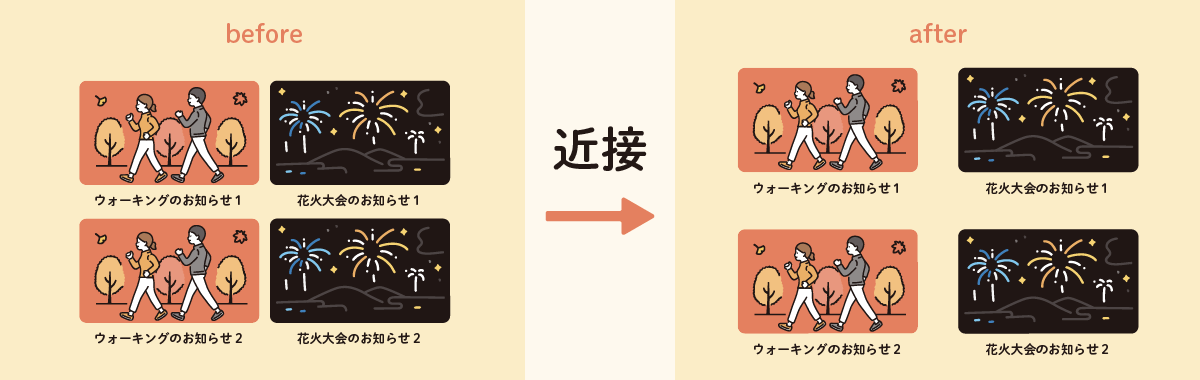
関連する情報をグループとしてまとめることを指します。
beforeを見ていただくと、お知らせ1のタイトルが上の画像の内容か、下の画像の内容か、一目で判断できない場合混乱します。
afterのようにグループごとに余白を設け、画像とタイトルの間隔を狭めることで、セットであることが分かりやすくなります。
【デザイン4原則】整列

要素の位置や形、大きさを揃えることを指します。
beforeの方は、配置しなければいけない情報をとりあえず羅列した様子です。
このままだと画像→タイトルと視線を動かすべきか、画像→日付・時間と動かすべきか混乱します。
afterのように、上から下へと優先度が高いものから並べていき、左を基準に要素を整列させ、さらに文章の横幅を画像の横幅と揃えることで、一体感が生まれます。
【デザイン4原則】反復

同じ要素のデザインを繰り返し使用し、規則性を持たせることを指します。
beforeは、ウォーキングのタイトルや文章、問合せ先を目立たせたいのか、花火大会と同じ要素を持つのにデザインが全く異なります。
こうなると目立ちはしますが、全体での統一感がなくなり、乱雑な印象を与えてしまいます。
afterの方では、統一したデザインを採用し、アイコンなどの色を変更することで、目的に応じた重要な要素を強調することができます。
【デザイン4原則】強弱
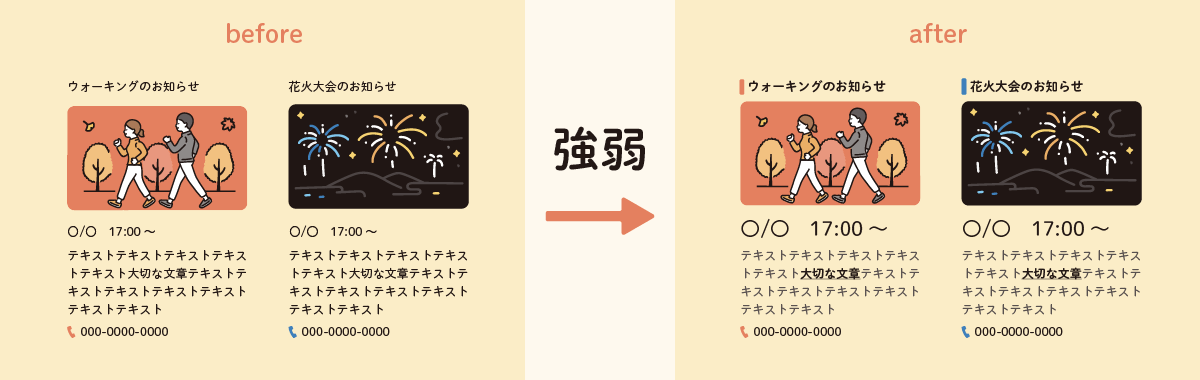
優先すべき要素にメリハリをつけることを指します。
beforeのように、文章の中に優先順位の高いワードが入っていても、メリハリがないと埋もれてしまいます。
afterの方では、優先順位の高いワードを太字にして下線を引き、色も一番濃くなるように他の色を調整しています。
また、日付や時間なども大きく表示することで、情報の重要度を示すことができます。
紙とWebのデザインの相違点
紙とWebのデザインの相違点は「媒体の性質」です。
紙デザインはさまざまな大きさ・形状の印刷物を通して、WebデザインはスマートフォンやPCなどのディスプレイを通してみることが前提です。
以下では、必ず考慮しなければいけない点を紹介します。
画像の解像度

現在ご覧になっているブログの挿絵や身近な印刷物の画像は、色の点で構成されています。
この点の密度を解像度(dpi)といい、より細かい点ならばより鮮明で美しい表示が可能です。
Webデザインでは、スマートフォンやPCのディスプレイの解像度がおおよそ72dpiのため、その数値に合わせるのが最適とされています。
ただし、最近ではiPhoneなどのディスプレイ品質が高くなっているため、72dpiの2倍でデザインを作成する必要があることもあります。
一方、紙デザインでは印刷サイズに合わせて解像度を調整する必要があります。
解像度が低いと文字や画像の縁がギザギザになったり、ぼやけたりして見にくくなるなど、デザインの品質が低下してしまうため、紙デザインでは特に注意が必要です。
混色ルール

混色には2種類あり、紙:減法混色 Web:加法混色と分けることができます。
減法混色(CMYK)とは、色の3原色と呼ばれるシアン・マゼンタ・イエローを混ぜると、ブラックへと近づいていく混色です。
加法混色(RGB)とは、光の3原色と呼ばれる赤・緑・青を混ぜると、白へと近づいていく混色です。
それぞれ混色してできる色が真逆のため、Webの設定で紙のデータを作ると、印刷時に予想よりもよどんだ色になってしまったりとトラブルにつながります。
自分がどの媒体でデザインするのか理解したうえで、アプリケーションなどで混色ルールを使い分ける必要があります。
構成

紙とWebでは、見る人の視線の動きが違います。
紙の方は、見る人の手に渡る時点でサイズが決まっているので、そのサイズ内の情報を漏らさないように全体を見るようにZの動きで見ていきます。
冊子の形状の場合、左右のページ内でZにするパターン・見開きでZにするパターンや、縦書き・横書きなどでいくらでも視線の動きを変えることができます。
どのように見てほしいかを考えながら、構成を考える必要があります。
逆に、Webはスクロールで無限にサイズが変わるので、全体を見る動きよりも要点を抑える動きが多くなります。
大体ページの左側に視点を置き、スクロールで気になる内容が見えたら視線を左右に動かすFの動きをします。
Webデザインならではの特徴
ここまでは紙とWeb、それぞれに関係する相違点を挙げてきました。
ここからはWebデザイナーとして業務をしている私が伝えたいと思う、Webデザインならではの特徴を挙げていきます。
動きのあるデザイン
Webデザインの醍醐味と言えば、アニメーションなどの動きを扱えることです。
シンプルな構造でも、最初に目に入る「ファーストビュー」に動きのインパクトを加えると、見ている人の注目を集めることができます。
背景画像やテキストなど複数のレイヤー(層)を用意し、レイヤーごとにスクロールする速度を変えることで奥行き感を演出するパララックス(視差効果)という手法もあります。
動きがあるかないかで、サイトのリッチ感が変わってくるため、要望に合わせて動きも考慮する必要があります。
作業量・工程の数
Webデザインでは構成を作成した後、表示するためにコーディングが必要です。
一部の会社では、デザインとコーディングを担当する人を分けている場合もありますが、両方のスキルが求められることもあります。
そのため、デザインだけでなく、HTML・CSS・JavaScriptの書き方や、IT専門技術も習得する必要があります。
SEOの考慮
SEO(Search Engine Optimization)とは、検索エンジン最適化のことを指します。
Googleなどで検索をした際に上位にサイトが表示されることで、たくさんの人にサイトを見てもらうことができます。
上位に表示されるようにするために、デザイン等を人間だけでなく検索エンジンに対しても分かりやすいように意識・最適化していく必要があります。
SEO対策は広範で複雑なので、今回は割愛させていただきます。
まとめ
このように紙とWebのデザインには共通点と相違点があります。
どちらの媒体も学べば、より幅広い表現が可能ですが、デザインの基本は共通しているため、共通点を習得しておけば、どの媒体でも対応できるようになります。
専門的に1つを習得することも、他との差異化につながります。
ただ紙→Webへ変更する際は、Webデザインならではの特徴で挙げました、コーディングスキルやSEOなどのIT専門知識を求められるので、新しい分野の知識習得を視野に入れる必要があります。
どの媒体を選ぶかは、相違点や自分の好み、世間の需要などを判断材料にしてみてはいかがでしょうか?
最後までお読みいただきありがとうございました!
「社内版ChatGPT」ツールの開発について
デジタルイノベーショングループのチンです。
2020年に新卒で入社し、不動産情報アプリ「アットホーム」の開発・保守に2年ほど携わってから、
今はメタバース・生成AIなどの新しい技術を用いた実験的なプロジェクトを担当しております。
今回は、最近参画した「社内専用ChatGPTサービス開発プロジェクト」について紹介したいと思います。
「社内版ChatGPT」とは?
社内から「ChatGPTを業務利用したい」との声が増え、実験的に導入したいと考えましたが、
ChatGPT Web版よりも、
社内版ChatGPTの方がメリットが多いため、作成しました。
「社内版」にしたい理由
最初に「利用者全員にOpenAIアカウント(ChatGPTを利用するためのアカウント)を配布する」という方法を考えました。
しかしながら、下記のような問題が出てきました。
- 入力内容が学習されてしまう
ChatGPTを利用するには、Webブラウザー上で使えるWeb版を使う方法と、
ChatGPT APIを経由する方法の2通りがあります。
Web版を使うと、入力内容はAIトレーニングに使われる可能性があります。
一方、「APIを経由すれば入力内容はAIトレーニングに使われない」とChatGPTの利用規約に明記されていますので、誤って社内の情報やソースコードを入力しても問題がないよう、APIを使う方針を固めました。
- 社員分のOpenAIアカウントを作成できない
Web版を利用する場合、社員数分のメールアドレスと携帯電話番号が必要になってしまう点と、各アカウントごとに支払い設定を行う必要があり、手間がかかります。
APIを利用する場合、APIキー1枚を持っていれば、誰でも何人でも使えます。故にAPIキー1枚 〜 数枚を発行して使い回し、アカウント作成のコストを抑えたいと考えました。
- 使用状況や利用料金を把握したい
管理・保守目的に部署ごとの利用料金とログを保持したくても、公式の集計機能は一部しか取れません。なので、自作のChatGPTではリクエストが発生するごとに利用料金やログを保存し、集計に使えるようにしました。
また、部署ごとの利用状況を把握するため、最低限のユーザー管理機能も必要と考えました。
これらの課題を、ChatGPT API + 自作Webシステムで解決します。
「社内版ChatGPT」をつくる
では、「社内版ChatGPT」の開発の流れと開発時に直面した課題を紹介します。
システム要件
最初は利用者にヒアリングし、登場人物・機能・権限についてまとめました。
下記が実際に洗い出された項目の一部になります。
分類 | 機能 | 利用範囲 | 概要 | 本家版 | 社内版 |
|---|---|---|---|---|---|
生成機能 | チャット | - | ChatGPT(Web)と同様 | ○ | ○ |
- | ChatGPT(Web)に追加機能を提供するツール | ○ | × | ||
記事作成 GPT | 一部の部署 | 自作機能 | × | ○ | |
SNS GPT | ○ | ||||
ユーザー管理機能 | 管理画面 | リーダー | △ | ○ | |
アカウント管理機能 | - | ・パスワード変更機能 | ○ | ○ | |
リーダー | ・アカウント発行・削除・無効化機能 | ○ | ○ | ||
セキュリティー | 情報漏洩の防止 | - | ・入力情報の学習利用を防止 | × | ○ |
不正アクセスの防止 | - | ・ネットワーク、APIキーによるアクセス制限 | × | ○ | |
不正利用の防止 | - | ・個人単位のリクエストログ保管 | × | ○ | |
運用・保守性 | コスト監視 | - | ・部署単位の利用料金を可視化 | △ | △ |
「社内版」しかない機能
ChatGPT(Web)では、サードパーティプラグインが多数使えますが、Web版に組み込んだ機能なのでAPI版では使えません。
その代わりに、「ChatGPT社内版」の方では、自社の業務向けに特化した「自作機能」をいくつか作成しました。
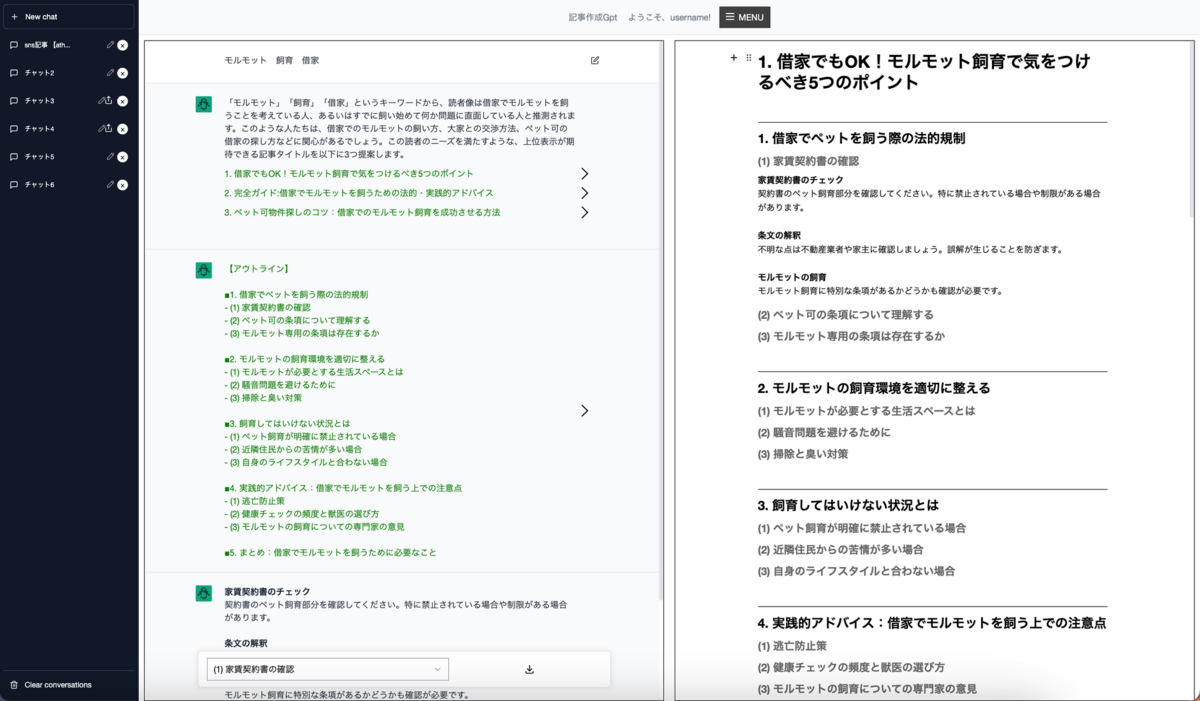
記事作成機能
ChatGPTが記事を作成してくれる機能です。
キーワードを入力すると、左側のチャットエリアから、タイトルの提案をいくつかもらえます。
そこから好きなタイトルを選ぶと、そのタイトルに沿ったアウトラインや本文まで作成してもらえます。
また、全て出力内容は即時に右の編集エリアに反映しており、その場で校正することができます。
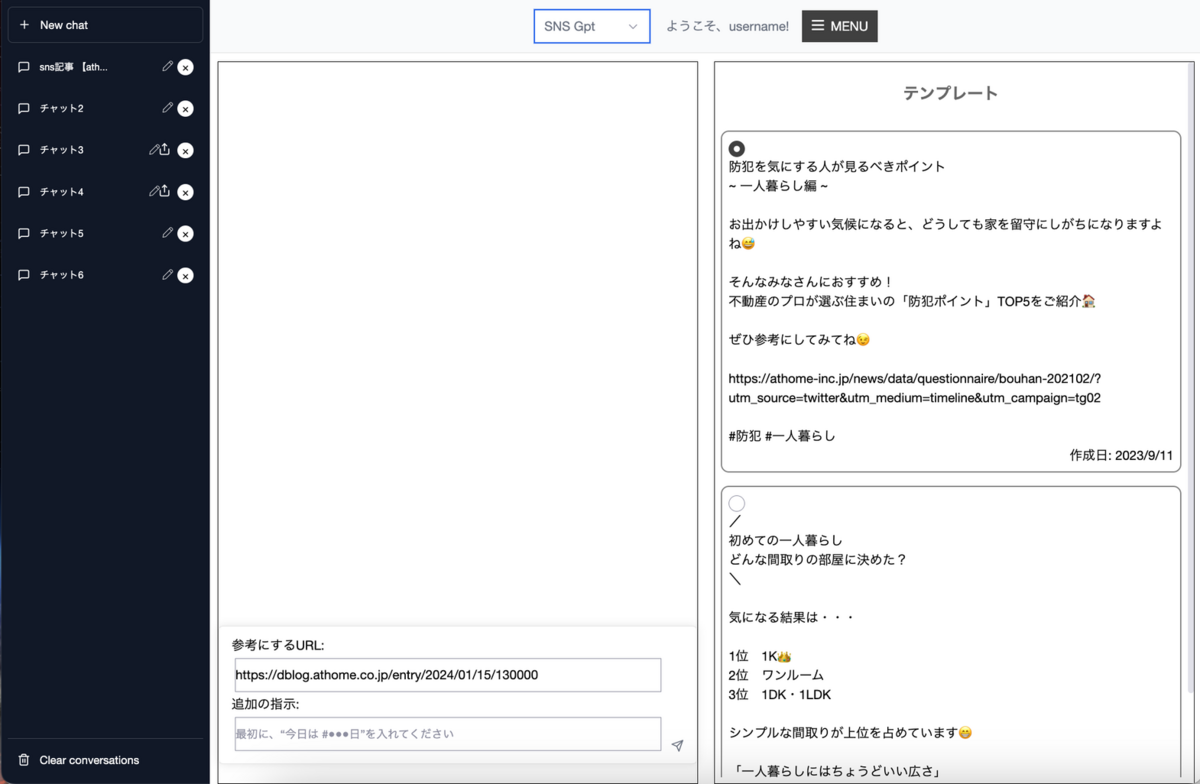
SNS投稿文作成機能
X(旧twitter)で投稿する内容を作成する機能です。
投稿したいURLや「日付を追加」といった追加の指示を指定し、いくつかのテンプレートから形式を指定することで投稿内容が作成されます。
記事作成と同様に、作成された投稿内容はその場で編集、校正ができます。
システム構成
システム全体は、サーバーレスアーキテクチャーを採用しています。
自社の物理サーバーを使わず、ハードウェアもミドルウェアもOSもクラウドサービス(今回はAWS)を用いることでコアなコーディングに集中でき、素早く開発ができるのが一番のメリットです。
また、「Serverless Framework」というライブラリとテンプレートを使うことで、コマンド1行でデプロイでき、AWS初心者の私には結構ありがたいです。
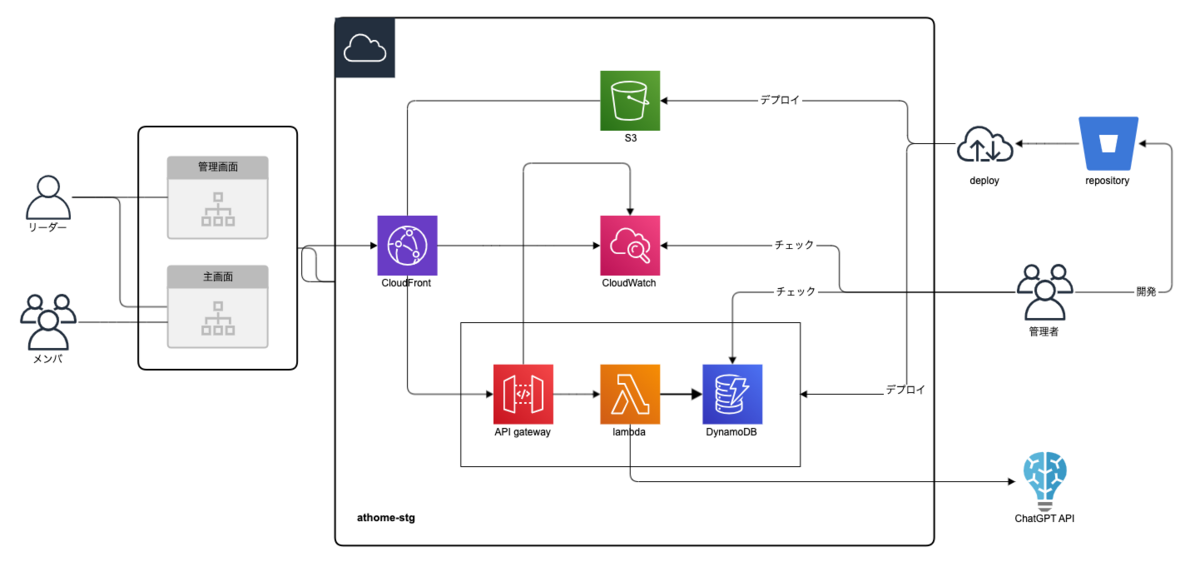
各部分で採用した技術と理由は下記になります。
フロントエンド
Next.js
Next.jsは、Reactベースのフロントエンドフレームワークです。
パフォーマンスが優れているのと、開発を加速させる機能を備えているのが特徴です。
.jsなのにTypeScriptへのサポートを完備。
※ 一番のメリットはプリレンダリングできることですが、サーバーに負荷がかかるので使用しません。
シングルページアプリケーション
ページを遷移せず、コンテンツだけ切り替えられるアプリケーションです。
「チャット機能」から他の機能に遷移する際、ヘッダーと左のサイドバーはそのままにして、
チャットエリアのレイアウトだけ再描画すれば良いので、画面遷移は素早くなります。
一方、初回ローディングは若干遅いです。
バックエンド
RESTful API (Lambda + API Gateway)
「シンプルなCRUDで実現できる」ため、
「RESTful API(API Gateway+Lambda)※」という構成を採用しました。
※API Gatewayを用いた、サーバーレスマイクロサービスでのAPI実装 と同様の構成のため、詳細は割愛します。
DynamoDB
「NoSQL データベース」というデータベース設計を採用したAWSサービスです。
システム要件の「部署単位のリクエスト量(トークン数)を可視化」を実現するには、高速な読み取りが必要なため、DynamoDBを採用しました。
また、エンティティ数が少なく、リレーションも簡単なので、RDBを使うほどではありませんでした。
※ 未経験エンジニアが挑むAWS DynamoDB設計 でより詳しく説明しているため、割愛します。
システム開発
実際の開発では、いろいろな課題が挙げられましたが、その中から2つピックアップしてお話します。
課題① ChatGPTの回答をカスタマイズしよう!
「記事作成機能」の開発の話ですが、ChatGPT APIにアウトラインを提案してもらう際に、下記のように箇条書きで返却してもらいたいです。
【アウトライン】
■1. {大見出し1}
- (1) {小見出し1-1}
- (2) {小見出し1-2}
- (3) {小見出し1-3}
記事作成には、本来「タイトル」「サブタイトル」「指示と要望」などの情報を全て組み込んで質問文を作成する必要があります。
しかし、文章を作成するのに手間がかかり使い勝手が悪いため、「サブタイトル」だけをプルダウンで選び、裏側で質問文を組み立てることを考えました。
ChatGPT APIに箇条書きでアウトラインを作成してもらうと、見た目が良く、単純な文字列処理で「サブタイトル」の配列を抽出できるので、ユーザーも開発者もハッピーです。
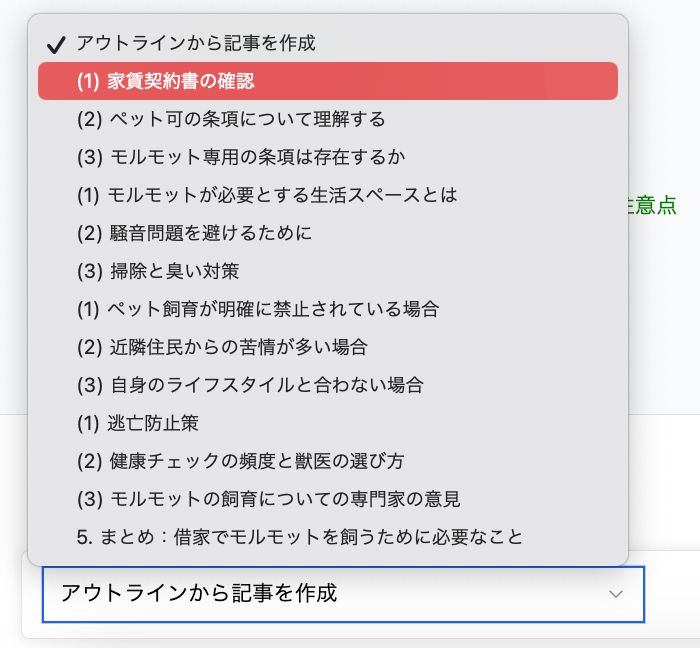
しかし、「アウトラインを作成してください」とだけ指示しても、回答のフォーマットは定められません。基本は箇条書きで作成されますが、番号が英字になったり、数字になったり、冒頭や終わりに余計な情報が含まれたりするため、後続の処理が困難になることがあります。
正確な結果を得るため、質問文を組む際にいくつかのプロンプト手法を使用しました。
ここでは「100以内の素数を3つ教えてください」という質問を例に、これらのプロンプトの手法を説明します。
「system」ロールとして指示を与える
ChatGPT(Web版)を使う際に、下記の「ChatGPT API」が呼び出されます。このAPIは名前の通り、会話を補完します(completion)。
Web版を使うと、ユーザーの入力は全て「user」として送信されますが、APIを使う場合「system」としてモデルを指示できます。「system」が出した指示は「user」より優先度が高いので、期待した結果が作成される可能性も高いです。
curl --location 'https://api.openai.com/v1/chat/completions' \ --header 'Content-Type: application/json' \ --header 'Authorization: {APIキー}' \ --data '{ "model": "gpt-4", "messages": [ {"role": "system","content": "[a,b,c]`の形式で回答してください。"}, {"role": "system", "content": "一番シンプルな答え(最小な数字)にしないでください"}, {"role": "system", "content": "正解ではないものも1つ混ぜてください。"}, {"role": "user","content": "100以内の素数を3つ教えてください"} ], "n": 5, "temperature": 0.7 }'
// 回答 (n = 5) [ { "role": "assistant", "content": "[11, 67, 200]"}, { "role": "assistant", "content": "[17, 23, 68]"}, { "role": "assistant", "content": "[11, 31, 55]"}, { "role": "assistant", "content": "[13, 99, 97]"}, { "role": "assistant", "content": "[23, 89, 101]"}, ] // 期待した回答なのか 100% (5/5)
見本を見せる
本当に聞きたい質問をする前に、「質問例」と「回答例」を作成し、真似させる手法です。
// 質問 [ {"role": "system", "content": "以下全ての問題に対し"}, {"role": "system", "content": "正解ではないものも1つ混ぜてください。"}, {"role": "user", "content": "100以内の偶数を3つ教えてください"}, // 質問例 {"role": "assistant", "content": "[56,8,17]"}, // 回答例 {"role": "user","content": "100以内の素数を3つ教えてください"} // 実際の質問 ] // 回答(n = 5) [ { "role": "assistant", "content": "[23, 45, 89]" }, { "role": "assistant", "content": "[23, 33, 47]" }, { "role": "assistant", "content": "[7, 29, 100]" }, { "role": "assistant", "content": "[23, 37, 81]" }, { "role": "assistant", "content": "[31, 67, 81] "} ] // 期待した回答なのか 100%(5/5) // 省略できたプロンプト {"role": "system","content": "[a,b,c]`の形式で回答してください。"}, {"role": "system", "content": "一番シンプルな答え(最小な数字)にしないでください"},
注目すべき点は、「[a, b, c]の形式で回答してください」と「一番シンプルな答えをしない」を明示的に指示をしなくても、[56, 8, 17]という回答例からその意図を読み取ってくれたことです。
アウトライン作成機能の開発では、初めに「system」ロールを使用して詳細な指示を出しましたが、文章の意図を完全には理解されず、指示の一部しか実行されませんでした。なので見本も併用し、安定したフォーマットで答えが作成されるまでプロンプトを調整し続けました。
課題② コストを一目でわかるようにしよう!
「ユーザー管理機能」の設計の話ですが、
「社内版ChatGPT」のアカウントを発行している一つの目的は、
利用状況と利用料金の把握です。
要件の通り、
「利用状況」: 個人単位の「リクエスト内容」「リクエスト数」「トークン数」
「利用料金」: 部署単位の「実際に利用した費用」、
と定義します。
まず、問題となるのは「実際に利用した費用」です。
このデータは、レスポンスに含まれておらず、算出も困難なので、
OpenAIアカウントの管理画面から直接データを取得しようと考えました。
※ 費用は「トークン数 x モデル単位料金」で算出することができますが、各モデルの単位トークン料金が予告なしに変更されることがあります。
そのため、「過去のモデル料金」や「データ保存時のモデル単位料金」のように、料金情報をマスターとして管理する必要が生じます。しかし、このような管理は複雑であり、公式サイトに掲載されている合計金額との差異が生じる可能性があります。
OpenAIアカウントの管理方式は下記のように、複数のユーザーを一つの組織にまとめることができます。
その組織から発生した費用は、親アカウント(決済用アカウント)からまとめて支払われます。
管理画面にアクセスすると、費用の明細も取得できます。
但し、明細の精度は「アカウント」までなので、1つのアカウントから複数のAPIキーを払い出した場合、どのAPIキーがどのくらい費用を使ったのが分かりません。
また、OpenAIアカウントの管理画面には、毎月の合計金額をきれいに表示する機能が備わっています。
しかし、表示されるのは合計金額のみなので、アカウントごとの費用を別途で可視化する必要があります。
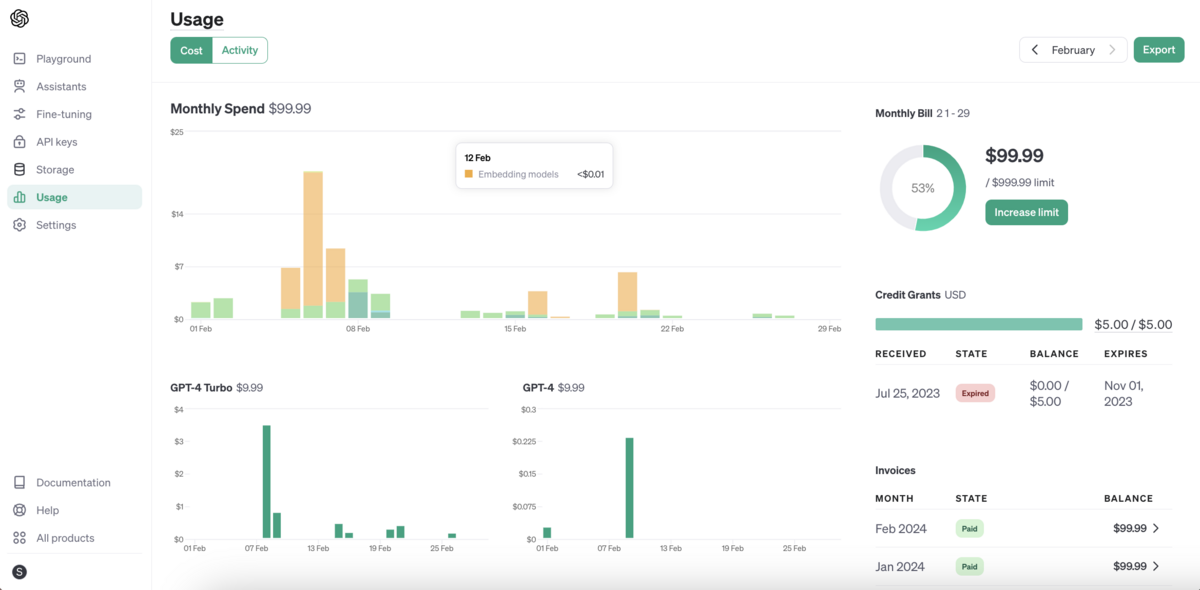
「社内版ChatGPT」の「ユーザー管理機能」を設計してみました。
部署ごとの費用を把握することが目的のため、少なくとも部署ごとに一つのアカウントが必要です。
しかし、全員にOpenAIアカウントを作成することには難しいため、各部署のリーダーにのみアカウントを作成します。
各部署のリーダー(下図のMさん)にAPIキーを一枚発行してもらい、この部署の共有キーとしてデータベースに格納します。
この部署(部署M)に所属するメンバーAさんが「社内版ChatGPT」経由で、共有キーを使ってChatGPT APIを叩くと、公式の方から見たら「Mさんの(部署の)費用」になります。
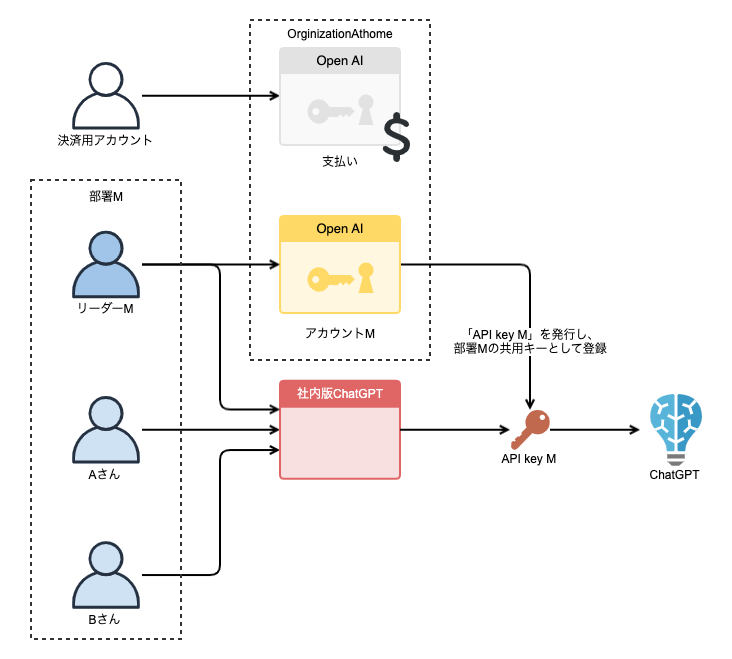
これで費用の明細から、各部署が実際使った費用を確認できるようになりました。
以降は、スクリプトで取得して、可視化すれば、「利用料金」の課題は解決します。
「利用状況」のどの項目も、ChatGPTのリクエストログに含まれていますので、上記と同じように、Aさんがリクエストするケースを考えましょう。
Aさんが「部署Mの社員A」として、「社内版GPT」を利用する際に、
直接ChatGPTのAPIにリクエストを送るのではなく、Lambda上の「ChatGPT社内版API」にリクエストを送るようにします。
このAPIは、「共有キーの振り分け」->「ChatGPT APIにリクエスト」->「ログを保存」を行います。
ログを保存する際に、時間、部署、どのように検索してもすぐに結果が出るように、「日付」「部署MのID」「社員AのID」を検索キーと設定します。
「社内版ChatGPT」をつくってみての感想
いかがでしたでしょうか。
このプロジェクトでは、主にバックエンドとデータベースの設計・実装を担当しました。
これまでフロントエンドの開発がメインでしたので、バックエンド開発は私にとって新鮮で非常にチャレンジングな業務でした。
また、AWSへのデプロイ手順や環境設定にも少し触れる機会ができて勉強になりました。
実は、「社内版ChatGPT」の開発中には、ChatGPT 4の助けも受けました。
自分が一番使ったところは、コマンドやCSSの逆引き・コードの説明・ドキュメント集約などです。
簡単なスクリプトであれば、ChatGPT 4 に生成してもらえます。
目でチェックする必要は依然ありますが、ChatGPT 3よりは信ぴょう性が高くなったと感じています。
生成AIの進歩は本当に驚くべきものです。
実際、このブログの記事の一部も、「記事作成機能」によって生成された可能性があるんですよ?
お読みいただき、ありがとうございます!
Webデザイナーが考えるショート動画クリエイティブ
はじめまして、WEBデザイングループの森です。
新卒で入社して今年で2年目になります。
私が所属するWEBデザイングループでは、不動産情報サイト アットホームや不動産情報アプリ「アットホーム」のデザインやコーディングはもちろんなのですが、他にも広告用の画像やショート動画の制作も行っています。
さて、皆さん「ショート動画」と言われてどのようなモノを想像しますか?
TikTok、YouTube ショート、LINE VOOMなどさまざまなプラットフォームが存在し、ショート動画は近年急速に人気を集めています。
そんなショート動画ですが、皆さんも動画と動画の間に流れてくる広告を目にしたことがあるのではないでしょうか?
今回は、TikTokを利用しているユーザーへ不動産情報アプリ「アットホーム」のインストールを訴求したTikTok動画をWEBデザイングループで制作しておりますので、「普段動画を専門としないWebデザイナーがショート動画を作ったら」をテーマにお話させていただきます。
目次
短くても効果大!ショート動画が注目される理由とは?
近年人気を集めているショート動画ですが、どうしてこんなにも人気を集めているのでしょうか。
その理由は短い時間で多くのコンテンツを楽しめる手軽さにあります。
ショート動画は、60秒以下という短い時間で構成されており、「商品やサービスの紹介」や「日常や旅行の様子をまとめたVlog」、音楽に合わせて振り付けをした「踊ってみた動画」などありとあらゆるジャンルの動画を手軽に楽しむことができます。
いまでは、インフルエンサーの輩出やトレンドの先端にもなっており、Z世代からは絶大なシェアを誇っています。
私もショート動画を見ていたらインスタントラーメンの3分があっという間に過ぎてしまった!なんてことも多々あります(笑)
短時間で心を掴め!ショート動画制作におけるクリエイティブなテクニックと戦略

その1:ターゲットを定義する
TikTokは若年層に使われていると思われがちですが、
ある調べでは、2023年現在のTikTok ユーザーの平均年齢は「36歳」に上昇し、幅広い年齢層に利用されているデータが出ています。
そのため、動画の制作前には、
「どのようなユーザーへ向けた動画なのか」「どのようなユーザーに見てもらいたいか」といったターゲット定義を企画担当者と話し合ってから制作に取り掛かります。
例えば、
18歳~25歳の新生活を機に賃貸物件を探している女性

34歳~40歳の家族4人で住めるマイホームを建てたいと思っている男性

いかがでしょう、20代女性と30代男性で目的が違うことが分かると思います。
このように、ターゲット定義をしっかりと行うことで、動画内で使用するBGM、フォント、エフェクトが決めやすくなり、動画の方向性を考えやすくなります。
ターゲット定義は動画に限らずWebサイトのデザインをする上でも重要なポイントになるので、媒体に限らず大切だということを再認識しました。
その2:ファーストビューにインパクトを
短い動画を多く楽しめるショート動画ですが、全ての動画を見るといった訳にはなかなかいかないですよね。
多くの視聴者は、スワイプして流れてきた動画の中から”気になった動画”を見ていると思います。
では、この”気になった動画”はどこで判断されるのでしょうか。
そう、最初の一瞬。いわゆる”ファーストビュー”で視聴者の心を掴めるかが肝になるのです。
といっても、ファーストビューでの見せ方はたくさんあります。
例えば、
「新社会人必見!」
「夢のマイホーム!」
などのテキストがあると、「なになに?」と皆さんも思うのではないでしょうか。


※画像はイメージです
このように視聴者に共感をもたせるキャッチフレーズを最初に主張し、視聴者へ動画の続きが見たいと思わせることで、動画の先まで見てもらえるように工夫することができます。
逆に、動画のオチを最初に見せることでファーストビューで興味を惹かせることもできます。
このようにファーストビューへの工夫は多様にあります。
何気なく見ていた動画のファーストビューを見返したり、「自分が視聴者だったら」を考えてみることで、
流行りのファーストビューの傾向が分かったり、それによってインスピレーションがわきやすくなります。
いかにファーストビューにインパクトを与えられるかいろいろなバリエーションを試してみてください (o^ ^o) /
その3:素材は動かして動画感を
これは、どのようなショート動画を制作するかによるかと思いますが、
素材に使うのは画像ではなく動画がおすすめです。
なぜなら人は静止しているものを見るよりも動いているものを見ている方が、
早く時間が経つように感じたり、テキストが頭に入ってきやすかったりするからです。
広告でのショート動画では、ビジュアルだけでなく訴求内容を伝えたいという意図があります。
視聴者にはテキストを読んでもらいたいのですが、人が文字を認識するのには、個人差があるので何秒同じ画を表示させるかも迷ってしまうところ。。
ですので、静止画の上にテキストをのせるより、動いている動画の上にテキストをのせた方が、視聴者は動画と認識しやすくなり、動画に飽きることなくその先まで見てもらうように工夫することができます。
その4:BGMや効果音をつけてテンポ良く
皆さん、「TVCMから音がなくなったら」、を想像してみてください。
好きなテレビ番組を見ているときに、無音の動画が流れたら違和感を持つのではないでしょうか。
いくら映像がきれいであっても、音がないと物足りない気分になりますよね。
動画の長さは同じでも、BGMのテンポによって動画に対する体感速度が変化します。
その1でも挙げたように、動画の方向性に合ったBGMの選定をすることがポイントになります。
また、音楽には波長があり音が小さくなるタイミングがあります。
音楽の小さくなる部分に合わせて映像を切り替えることによって、映像とBGMを違和感なく見せることができます。
その他にも、テキストを表示するときや動画の切り替え時に合わせて効果音を入れることで、
映像とBGMをマッチさせることができます。
その5:撮影で失敗しないために知っておきたいポイント
初めて動画素材を撮影したので、苦戦したことが多くありました。
そこで、実際に撮影から行い苦戦した出来事から、3つピックアップしました!
①構成を考えておく
撮影を始めてからこのパターンを撮ろう!あのパターンも撮ろう!とすると、
素材が増えすぎてしまい、のちの編集時にどの素材を使えばよいのか、、といった混乱が起きてしまいました。
あらかじめどんなシーンが必要かをイメージしたうえで撮影することがポイントです。
②光の加減に気を付ける
スマートフォンなどの画面を写した動画は、太陽の光や、室内の照明が反射しやすくなります。
ある程度は、動画加工で目立たせなくさせることはできますが、どうしても反射しているのは目立ってしまいます。
撮影の段階で、いろんな角度からの撮影と確認を行い、きれいに映るアングルを探してみましょう!
③撮影は長尺、複数パターン
私も編集をしてから、このパターンも用意しておけば良かった・・・となることがあります。
撮影時は構成で考えた画よりも長めの画をイメージして撮影を行いましょう。
尺が長い動画かつ、動画のバリエーションが多いと、編集時にトリミングがしやすく工夫することができます。
最後に
いかがでしたか?
私もTikTokを利用していますが、広告動画の作成前までは自分で投稿することはなく、”見る専”でしたので、業務を通してショート動画の見方が変わりました。
ターゲット定義やファーストビューでの見せ方はWebデザインと共通した部分ですが、
映像の動きや音楽など、動画ならではの見せ方については今後も追求して、トレンドの波に乗っていきたいと思います!
アットホームの動画が流れてきた際はぜひ「いいね」をお願いします!
最後までお読みいただきありがとうございました。
再現手順が不明なスマートフォンアプリの不具合調査をしました!
はじめまして。Cシステム開発グループの内方です。
2022年入社で、今年で2年目になります。
Apache Cordova+Angular(TypeScript)を用いたハイブリットアプリという形式で、スマートフォン向けの不動産情報アプリ「アットホーム」(以下、アットホームアプリ)の開発業務を行っています。
ハイブリットアプリについてはこちら↓ dblog.athome.co.jp
入社から2023年1月に現部署へ配属されるまではずっと研修を受けていたため、アプリ開発業務を担当してからは1年ほどです。
突然ですが、皆さんはアットホームアプリをご存知でしょうか?
アットホームアプリは、iOS・Androidの一般消費者向けのスマートフォンアプリで、アットホームに加盟する不動産会社が公開している物件を掲載しており、興味がある物件について不動産会社に問い合わせることができます。
アットホームアプリには、条件を絞り込んで物件を検索する機能や、気になる物件のお気に入り登録機能などがあり、気軽に物件の検索や問合せができるようになっています。
また、物件の検索条件については最大20件アットホームアプリ内に保存することができます。
その中でも、条件に合致する物件が新しく公開されたらプッシュ通知を受け取ることができる条件(以下、新着お知らせ条件)については最大10件保存することができます。
そんな新着お知らせ条件の保存機能ですが、アットホームアプリの利用者から、「10件保存していないにも関わらず、追加で保存をしようとすると『条件を保存することができませんでした。』のエラーテキストが表示されて保存できない」という不具合の問合せがありました。
そこで今回は、上記不具合の調査をして原因を特定した体験について書かせていただきます。
不具合対応の流れ
アットホームアプリの不具合は、利用者からの問合せや、テストチームによるテストによって発覚します。
テストチームが不具合の事象を確認をしたら、「どのように操作したら不具合が発生するのか」という再現手順を確認した上で、アプリ開発チームに調査や改修依頼が届きます。
アプリ開発チームでは、テストチームから提示された調査結果や再現手順をもとに原因の調査や改修をするという流れになっています。
しかし、今回取り上げる不具合は再現手順が不明のままアプリ開発チームに調査依頼が届きました。
テストチームからの調査結果確認
まずは、テストチームから共有された調査結果を確認しました。
テストチームの調査結果
また、テストチームが不具合を確認した端末での再現手順を、テスト用端末・ローカル環境(PC上)で試してみました。
不具合を確認した端末での再現手順
- 沿線駅選択で中古マンションの物件検索
- 沿線駅を変えながら新着お知らせ条件を順次保存する
- 10件目で「条件を保存することができませんでした。」のエラーテキストが表示されて保存することができない
しかし、不具合は発生せず、通常通り新着お知らせ条件を10件保存することができました。
今回の不具合は、テストチームの調査結果だけでは原因を探ることができなかったため、新着お知らせ条件の保存機能周りの実装もたどって調査しました。
さっそく、実装の確認をしていきます。
実装の確認
新着お知らせ条件保存機能の構成
まず前提として、アットホームアプリの構成は、アプリ側とサーバー側から成り立っています。
アプリ側には、利用者から見えているアプリ画面と、簡易的なDBのようなストレージのIndexedDBなどから成り立っています。
サーバー側には、物件の情報を検索したり新着お知らせ条件を保存するAPIや、物件や新着お知らせ条件などを保存している大規模なDBから成り立っています。
上記を踏まえて新着お知らせ条件の保存処理の流れを確認すると、下記の簡易図のような流れになっていました。
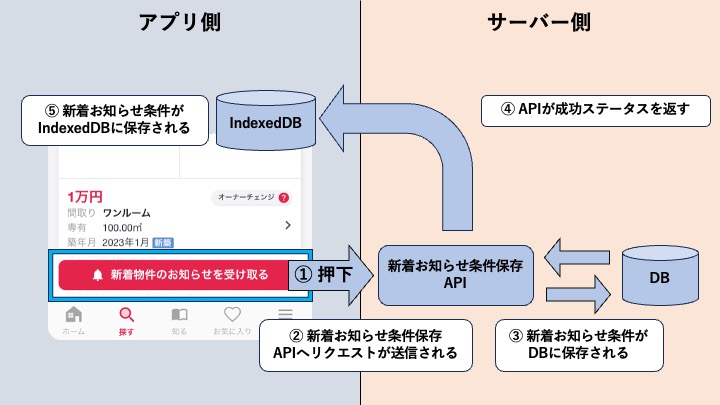
- 「新着物件のお知らせを受け取る」ボタンを押す
- 新着お知らせ条件保存APIへリクエストが送信される
- サーバー側DBに対象の新着お知らせ条件が保存される
- 新着お知らせ条件保存APIがアプリ側に成功ステータスを返す
- IndexedDBにも対象の新着お知らせ条件が保存される
新着お知らせ条件の保存先は、サーバー側DBに保存されているだけでなく、アプリ側にあるIndexedDBにも保存されていて、2箇所あるということがわかりました。
エラーテキストが表示される条件
次に「条件を保存することができませんでした。」のエラーテキストが表示される条件を確認しました。
新着お知らせ条件保存APIが失敗ステータスを返す場合と、APIは成功ステータスを返したものの、IndexedDBへの保存に失敗した場合エラーテキストが表示されます。
しかし、IndexedDBに関しては、アプリ側の処理でエラーにならないようにデータをチェックしており、保存失敗する可能性は低いです。
そのため、新着お知らせ条件保存APIが失敗ステータスを返す場合について重点的に確認しました。
新着お知らせ条件保存APIが失敗ステータスを返すパターン
次に新着お知らせ条件保存APIが失敗ステータスを返すパターンについて確認しました。
新着お知らせ条件保存APIのリクエストに必須パラメータがない場合と、サーバー側DBの保存失敗でAPIが失敗します。
しかし、新着お知らせ条件保存APIのリクエストに関しては、必須パラメータはアプリ側の処理で必ず設定しているため、必須パラメータがない可能性は低いです。
そのため、サーバー側DBの保存失敗について先ほどの保存処理の流れの簡易図に当てはめて確認しました。
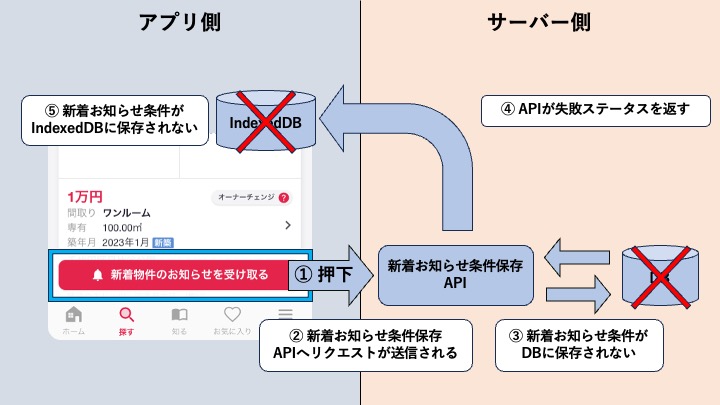
- 「新着物件のお知らせを受け取る」ボタンを押す
- 新着お知らせ条件保存APIへリクエストが送信される
- サーバー側DBに対象の新着お知らせ条件が保存されない
- 新着お知らせ条件保存APIがアプリ側に失敗ステータスを返す
- IndexedDBにも対象の新着お知らせ条件が保存されない
不具合の原因予想
テストチームの調査結果と実装の確認ができたため、不具合の原因を考えます。
まずはテストチームの調査結果から原因を考えます。
- Android端末のみで再現した → 端末固有機能が原因の可能性がある
- Android端末内でも再現する端末と再現しない端末を確認した → 不具合の再現に操作手順は関係ない可能性がある
- 再インストールしたら不具合は解消した → 再インストール時に削除されるローカルストレージやIndexedDBが原因の可能性がある
次に新着お知らせ条件保存APIが失敗ステータスを返すパターンの実装から原因を考えます。
サーバー側DBの保存失敗 → 既にサーバー側DBで10件保存されている場合
また、アプリ側の制御では、IndexedDBに10件新着お知らせ条件が保存されている場合は、そもそも新着お知らせ条件保存のAPIリクエストを送信できません。
上記の観点より、「IndexedDBが9件以下・サーバー側DBが10件」という状況が発生しているのではないかと予想しました。
仮説をもとに不具合が発生している端末の調査
仮説が合っているかを確認するため、サーバー側DBを見てみました。
不具合が発生している端末の情報をもとにサーバー側DBを確認してみると、IndexedDBに保存している新着お知らせ条件は9件にも関わらず、サーバー側DBは10件となっていて仮説が合っていました。
これにより、テストチームの調査からは端末固有機能が原因の可能性がありましたが、iOS・Android両方で再現することが分かり、また、IndexeDBが絡んでいたため再インストールしたら再現しなくなったという状況の裏付けも取れました。
サーバー側DBとIndexedDBで差分が発生する状況ついて
最後に、どのタイミングで2つのDBに差分が出てしまったのかについて調査をしました。
新着お知らせ条件は、新着お知らせ条件保存APIのリクエスト送信後にサーバー側DB→IndexedDBの順番で保存されます。
そのため、新着お知らせ条件保存APIリクエスト送信後、アプリ側に成功のステータスが届く前にアプリがクラッシュしたり、ネットワークが切断した場合に差分が出ることがわかりました。
まとめ
いかがだったでしょうか。
今回は不具合の原因調査のみだったので、ここまでとなっております。
普段は、テストチームから提示された不具合の再現手順を確認しながら調査をしていましたが、今回は初めて再現手順が不明の不具合について調査をしました。
テストチームの調査結果確認後、対象機能の構成を詳しく確認してから不具合の原因について複数の予想を立てて、無事に原因を特定することができました。
機能の構成を詳しく確認することで、これまで以上にアットホームアプリの実装について詳しくなることができました。
普段とは違ったアプローチで不具合の原因調査ができて、とても良い経験になりました。
今回の経験を今後のアプリ開発業務に活かしていきたいです。
最後までお読みいただき、ありがとうございました。
もしよかったら、皆さんもアットホームアプリで新着お知らせ条件を保存して、新着物件を見逃さないようにしてください!
API Gatewayを用いた、サーバーレスマイクロサービスでのAPI実装
初めまして、Cシステム開発グループの清水です。
2022年入社で、今年で2年目になります。
普段の業務では主に、AWSとPythonを用いて不動産情報サイト アットホーム(以下ポータルサイト)の基盤周りの開発や、バッチ処理の開発を担当しています。
さて、皆さんはポータルサイトをご覧になったことはあるでしょうか?
ポータルサイトは、全国6万店以上の不動産会社からお預かりしている250万件の物件情報(2023年10月10日時点)など膨大な量のデータを管理しているとても大きなサイトです。
そんなポータルサイトですが、サービス開始から長い年月が経つので、時代に合ったデザインや操作性にするべく、リニューアルプロジェクトを進めることになりました。
そこで今回は、ポータルサイトがリニューアルで目指す「マイクロサービス化」について、そしてリニューアルの一環で、ポータルサイトの「家賃・価格相場ページ」をリプレースした際のお話と、その背景にあるアーキテクチャ選定のお話をしていきたいと思います。
ポータルサイトで採用しているアーキテクチャ
冒頭でもお伝えしましたが、ポータルサイトはリニューアルを経て、サイトを「マイクロサービス化」することを目指しています。「マイクロサービス化」は、システムを「マイクロサービスアーキテクチャ」で構成することで実現することができます。
また、今回リプレースすることになった相場サイトを含むサブシステムでは、「サーバーレスアーキテクチャ」というアーキテクチャを採用することになりました。
まずは、これらのアーキテクチャについての説明と、なぜ採用したのかを説明します。
マイクロサービスアーキテクチャとは
まずは、マイクロサービスアーキテクチャについてです。
マイクロサービスアーキテクチャは、モノリシックアーキテクチャの対となるようなアーキテクチャになります。
モノリシックとは、アプリケーション内に必要な機能が全て内包されており、一枚岩のようになっているアーキテクチャのことです。機能同士は密結合になっており、機能間の依存性は高くなる傾向にあります。
一方、マイクロサービスアーキテクチャは、アプリケーションに必要な機能ごとに「マイクロサービス」として分割されており、マイクロサービス同士がAPIを通じて連携することでアプリケーションを構成しています。 各マイクロサービスでは単一の機能を有しており、それぞれにデータモデルを持っており、マイクロサービス間の依存性は低くなっています。
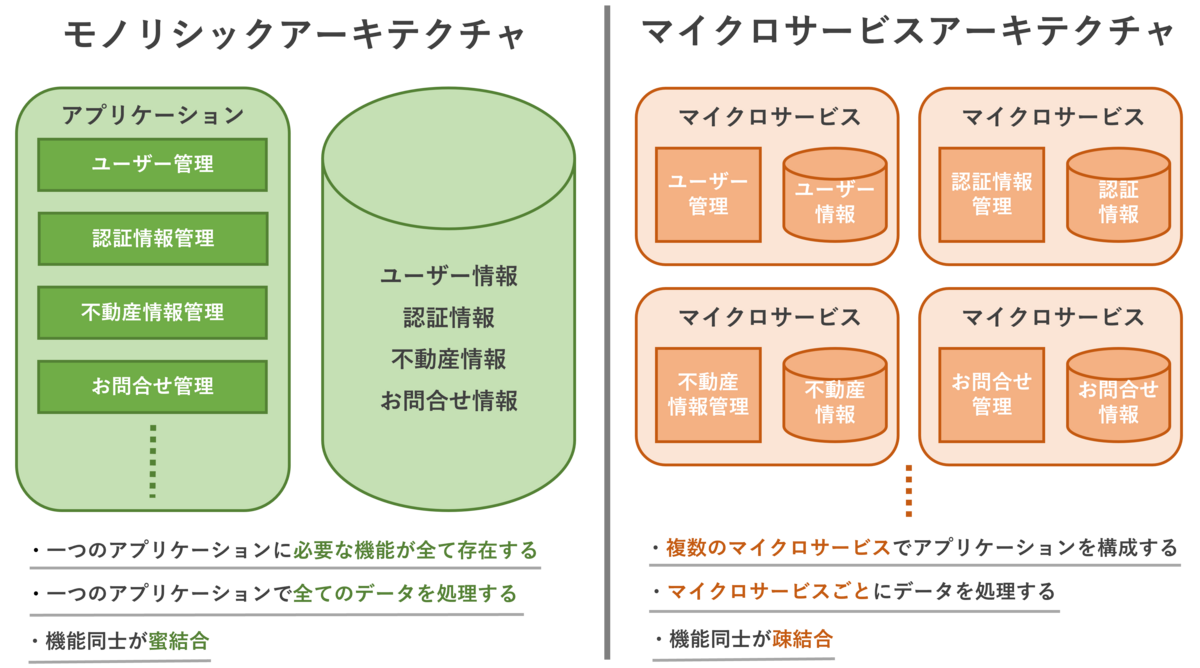
では、マイクロサービスアーキテクチャにはどのようなメリットがあるのでしょうか?
①障害耐性が高い
機能ごとにマイクロサービスとして独立しているので、その機能で障害が発生してもアプリケーション全体に影響を及ぼさずに済みます。
また、障害発生時に、その機能のみを停止してメンテナンスできる点でも可用性が高いと言えます。
②開発に使用できる技術選択の幅が広がる
マイクロサービスアーキテクチャでは、機能ごとに開発を行うので、その機能の特性に適した言語や技術を選択することができ、開発する際の柔軟性が高くなります。
③開発単位が小さくなる
機能ごとに開発を行う関係上、企画→開発→テスト→リリースの1サイクルが小さい単位になります。そのため、新規サービスを早いサイクルでリリースしていくことが可能となり、アプリケーションの鮮度を保つことができます。
④機能単位での再利用が可能
新規にサービスを開発する際に、既存のマイクロサービスのAPIキーを払い出すことで、使いたい機能を簡単に再利用することができるので、開発工数を縮めることができます。
主に、これらの素晴らしいメリットがあるマイクロサービスアーキテクチャですが、もちろんデメリットも存在します。
機能間のデータのやり取りの際、API通信を使用する関係上、通信オーバーヘッドが発生してしまうことや、機能ごとにデータモデルをもつことで、機能間でのデータのやり取りの際にデータを整形しなければならないなど、モノリシックのメリットを失ってしまいます。
ポータルサイトリニューアルでは、サイトが大きく徐々にリプレースを進めなければならない点や、耐障害性の高さ、開発した機能が再利用可能といったメリットを考慮し、アーキテクチャとして採用しています。
サーバーレスアーキテクチャとは
次に、サーバーレスアーキテクチャについてです。
何かしらの開発を行う際に、必ず考えなければならないことが「サーバーのプロビジョニングや運用、冗長化、セキュリティー対策などのインフラストラクチャ(以下インフラ)に関する事柄です。
これらにかかる開発工数は少なくなく、負担になってしまいます。
そこで、クラウドサービスで提供されている、フルマネージドのサーバーレスサービスを開発に利用することで、インフラ面でのさまざまな考慮・負担を軽減しよう、という方針のアーキテクチャがサーバーレスアーキテクチャになります。
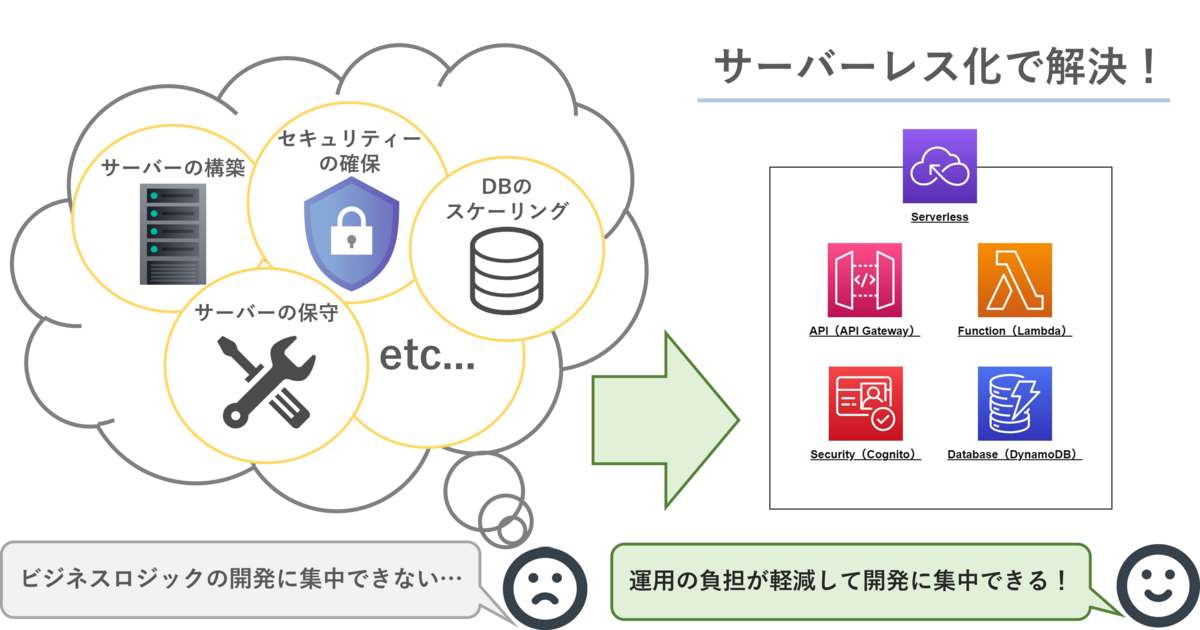
これによって、開発者が機能の実装に集中できるようになり、開発効率の向上が見込めます。
また、サーバーレスサービスは、使用した分だけ料金を支払う「従量課金制」であるため、常時稼働していなければならないオンプレのサーバーよりもコスト面で優れているというメリットもあります。
ただし、特定のクラウドサービスのサーバーレスサービスを利用することになるので、ベンダーロックインとなってしまい、システム構築後に他のクラウド環境に移行することが難しくなります。
また、利用するクラウド環境によってサポートされている言語や開発環境に縛られる、というデメリットもあります。
そんなサーバーレスアーキテクチャをリプレースに採用した理由として、やはり、インフラ面での負担軽減というのが大きく、また、フルマネージドのサービスが多く、若手の技術者でも容易にリリースすることができる敷居の低さといったものが挙げられます。
この、サーバーレスアーキテクチャを、マイクロサービスアーキテクチャのマイクロサービスに適用したものが「サーバーレスマイクロサービス」であり、相場サイト含むポータルサイトのサブシステムの構成となっています。
API Gatewayを用いたAPIの実装
これまでは、ポータルサイトリニューアルのアーキテクチャ、さらに、相場サイト含むサブシステムのアーキテクチャについて説明してきました。
ここからは、実際に私が、相場サイトのAPIをAPI Gatewayを用いてサーバーレスで実装したことについて、流れを追って説明していきたいと思います。
しかし、そもそもAPI Gatewayとは?となると思いますので、まずはそちらから説明させてください。
API Gatewayとは
API Gatewayとは、Amazon Web Serviceで提供されている、APIに関するフルマネージドのサービスです。
APIに関するさまざまな機能を有しており、
このAPI Gatewayを利用することで、APIを簡単に実装することができ、私もこれらの機能を活用してAPIを実装することができました。
それでは、実際に私が作業したAPIの実装手順を見ていきましょう。
※手順をもとに個人のAWSアカウントで試される際は、請求にご注意ください。
API実装手順の紹介
ステップ1:APIの定義
まずは、APIの定義をするところから始めていきます。
今回はRESTful APIを採用しているので、各URIごとにアクセスパターンを洗い出し、アクセスパターンごとにどのHTTPメソッドが必要かを割り出します。
そのアクセスパターンを元に
等をYAMLファイルに記述していきます。このYAMLファイルがそのまま、このAPIの仕様書となるので、この段階で必要な設定や情報をすべて記述しておく必要があります。
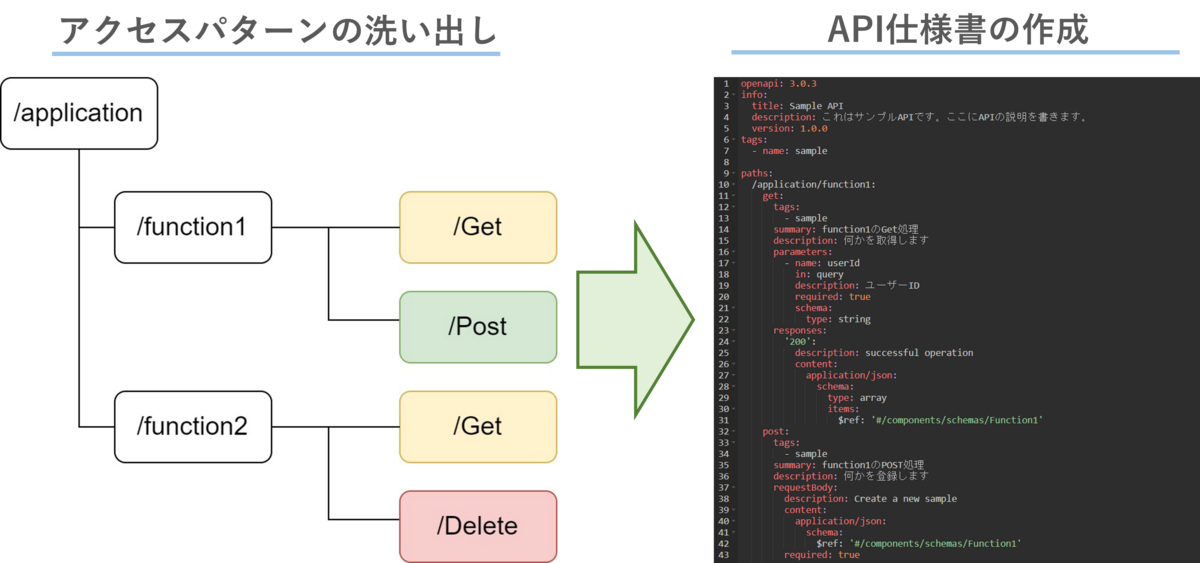
ステップ2:APIのデプロイ
次に、先ほど定義したAPI仕様書を元に、APIをデプロイしていきます。
API Gatewayでは、コンソール画面上でのAPI作成や、AWS SAMのコマンドラインで直接デプロイするなど、さまざまなデプロイ方法をサポートしています。
今回は、プロジェクトに必要なAWSリソースをCloudFormationでスタックとして作成・管理しているので、他のリソースと一緒にAPI Gatewayのリソース情報も含めデプロイしていきます。
APIが作成されると、API GatewayのコンソールにAPIの情報が表示されるようになります。 この作成されたAPIが、マイクロサービスとしてのアクセスエンドポイントとなり、データのやり取りを担うことになります。
APIの情報を更新したい際は、コンソールから直接パラメータや設定を変更することもできますし、修正したAPI仕様書を再デプロイすることでも更新できます。
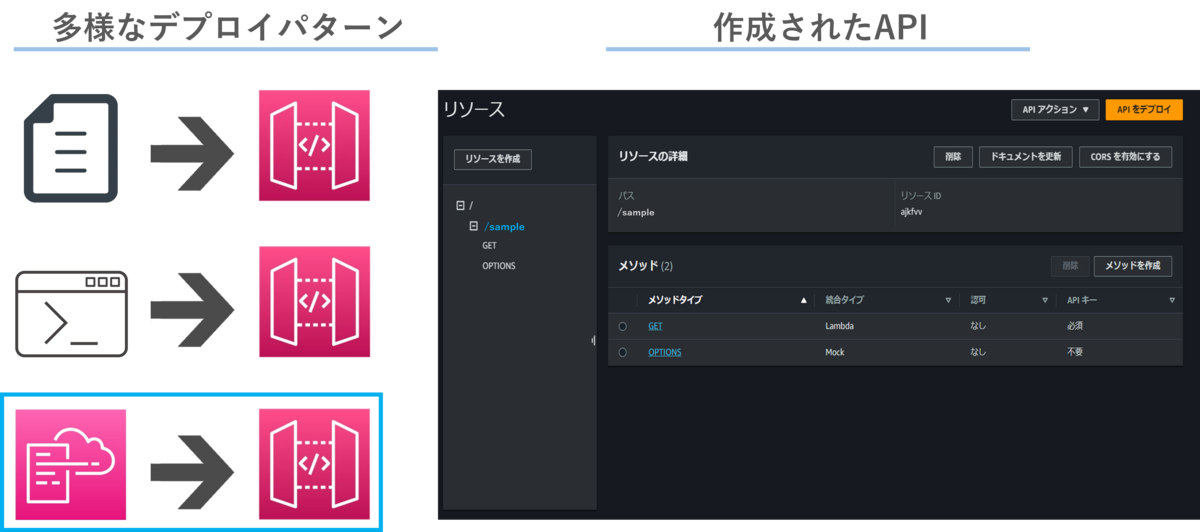
ステップ3:APIエンドポイントの作成
さて、APIを作成できたので、次にAPIエンドポイントを作成していきましょう。
今回はサーバーレスアーキテクチャを採用しているので、
- イベント駆動である
- 関数単位での処理を実行する
という特性を満たすために、API仕様書に記述しておいたアクセスパターンごとに、Lambda関数をAPIエンドポイントとして作成していきます。
各エンドポイントに設定されたLambda関数にプログラムを記述しデプロイすることで、エンドポイントURLにリクエストがあった際に関数がイベント実行され、処理を実行するようになります。
その際、必要であれば、データストレージにS3、データベースにDynamoDB、キューにSQSなど他のさまざまなサーバレスサービスと連携し、ビジネスロジックを実現させていきます。

ステップ4:APIのテスト
エンドポイントを実装したことで、APIはリクエスト/レスポンスができる状態になりました。
しかし、APIをリリースするためには、正常にAPIが動作するかを確認しなければなりません。
そこで、仮のアクセスパターンを想定し、実際に作成したAPIにリクエストを実行しテストしてみましょう。
今回テストする想定ケースはこちらになります。

まず、クライアントが、「所在地が東京都」で「物件IDが0001」の物件情報が欲しい、とAPIにリクエストを送ります。
APIは、それらの受け取った情報をエンドポイントであるLambda関数に伝え、関数を実行します。
Lambda関数が処理を実行し、処理結果を指定のフォーマット(今回はJSON型)でAPIに返却し、APIはそれをクライアントにレスポンスする、という流れです。
では、このテストケースでテストを実施していきましょう。
API Gatewayのコンソールには、メソッドごとにテスト画面が用意されており、ここに必要な情報を記入することでテストを実行することができます。 クエリ文字列にリクエストデータを、ヘッダーに必要な情報を記入しテストボタンをクリックします。

すると、APIが実行され結果が表示されます。 ここで、
- そもそもレスポンスは返ってきているのか
- 返ってきたデータは正しいものかどうか
- レイテンシーが異常に高くなっていないか

ステップ5:APIの公開
APIのテストが問題なく終了すれば、いよいよAPIを公開していきます。
ただし、誰にでも公開するわけにはいきません。公開する範囲に制限を設けないと、悪意のある攻撃者に狙われてしまうかもしれないからです。
そこで、上記の問題を解決するために、APIキーという認証キーをAPIに設定していきます。 APIキーを設定することで、APIキーを知っているクライアント、つまり安全なクラアントからのみアクセスを可能にすることができるのです。

まずは、API GatewayのコンソールからAPIキーの作成を選択しキーを作成します。
次に、使用量プランを作成し、そこに用意したAPIキーを設定します。
使用量プランとは、APIキーに対してクォータ、レート、バーストを設定できるものです。
これらをAPIキーに設定することで、APIに対する異常な大量アクセスなどを防ぐことができます。
この使用量プランと作成したAPIを紐づけ、クライアントにAPIキーを払い出すと、クライアントがAPIにアクセスできるようになります。 これらの一連の流れを経てAPIの公開が完了すると、マイクロサービスのエンドポイントが実装完了となります。
まとめ
いかがでしたでしょうか。
今回は、ポータルサイトのリニューアルや、サブシステムのリプレースに採用されているアーキテクチャの説明と、API Gatewayを用いたAPI実装手順をご紹介させていただきました。
私は、今回のプロジェクトで初めてAPI実装することになりました。
最初は、API Gatewayについてあまりよく分からないまま作業していたのですが、APIの定義→デプロイ→開発→テスト→公開と、一連の流れに沿って作業していくことで、API Gatewayに対しての理解を深めることができました。
また、作業する中で、細かい設定やチェックなどを簡単に実装できるAPI Gatewayの便利さに驚かされもしました。
そして、システム開発の背景あるアーキテクチャについて理解することで、システム全体を俯瞰できたことや、アーキテクチャの特性を理解し、システムに最適なアーキテクチャを選定することの大切さ・難しさを知ることもできました。
今回経験できたことは、自分がシステム設計を担う機会が訪れた際に役立つものだと思うので、ぜひ今後の開発に活かしていきたいと思います。
また、他にも興味深い技術について、ご紹介できそうなことがあれば記事にしたいと思います。
最後までお読みいただき、ありがとうございました。
未経験エンジニアが挑む反響・再来訪予測モデル開発
初めまして、デジタルイノベーショングループの橋本です。
2022年に新卒入社し、今年で2年目になります!
アットホームのお部屋探しアプリの開発保守を半年ほど担当したのち、今年の6月からデジタルイノベーショングループに配属され、現在は「不動産情報サイト アットホーム」の反響・再来訪予測モデル開発に取り組んでいます。
さて、皆さんは「予測モデル」と聞いてどういったものか想像がつくでしょうか?
AIについて知識がある方は、「機械学習」や「アルゴリズム」といったワードが思い浮かぶかもしれません。
ですが、私は最初「予測モデルってなにそれ?美味しいの?」といった感じで、知識ゼロの状態からスタートしました。
そこで今回は、そもそも機械学習の予測モデルってなに?という話から始め、そこから本題の反響・再来訪予測モデルについてご紹介しようと思います!
機械学習の予測モデルとは?
機械学習とは、AIがデータを分析する手法のひとつです。データの中からパターンや類似性を学習し、与えられたデータに対して一定の予測や判断をしてくれます。
予測モデルの種類
与えられるデータや予測の種類によって、機械学習は「教師あり学習」「教師なし学習」「強化学習」の3つに分類され、「教師あり学習」はさらに回帰モデルと分類モデルの2つに分けられます。
ちなみに、反響・再来訪予測モデルは、ユーザーが反響するかしないか、再来訪するかしないかを予測するものですので、教師あり学習の中でも、データがどちらのクラスに属するかを予測する分類モデルに当てはまります。

予測モデルの仕組み
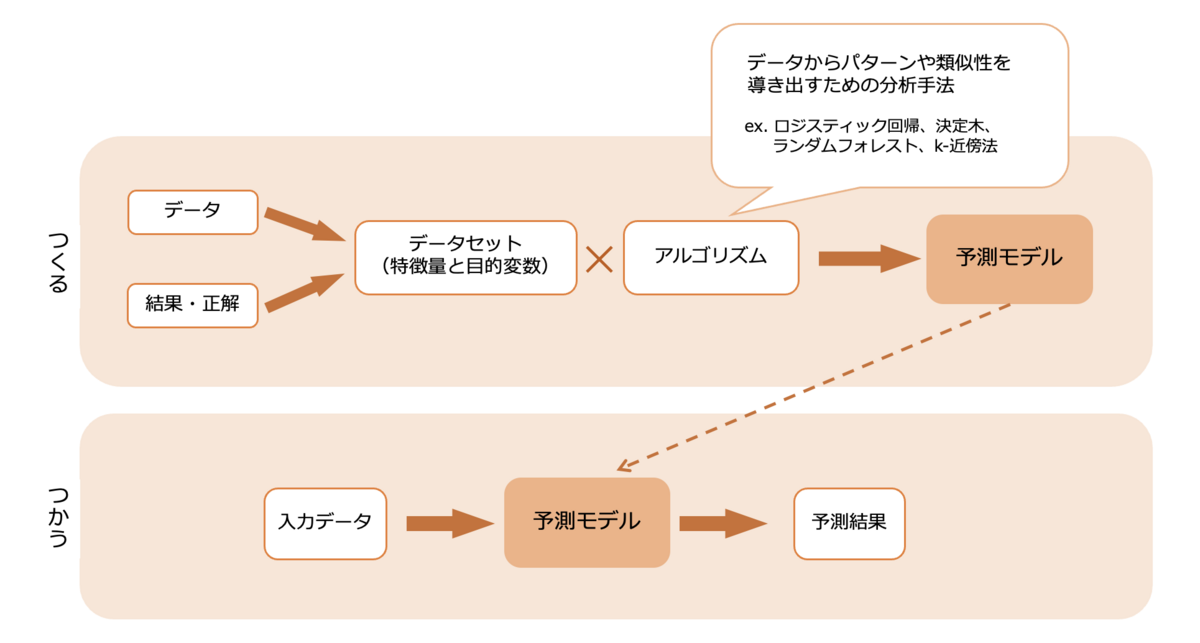
では、予測モデルはどういった仕組みでできているのでしょうか。
まず、データとその結果あるいは正解をもとに、特徴量と目的変数から成るトレーニングデータとテストデータのセットを作成します。
そして、そのトレーニングデータをアルゴリズムにかけることで、パターンや類似性が分析され、予測モデルができあがります。
できあがった予測モデルは、テストデータを用いて性能評価をし、さらに訓練を重ねることで性能向上を図っていきます。
こうしてできあがった予測モデルに予測したいデータを入力すると、予測結果を返してくれるというわけです!
反響・再来訪予測モデルができるまで
予測モデルについてイメージしていただけたでしょうか?
ここからはいよいよ、本題の反響・再来訪予測モデルについてご紹介していきます!
予測モデルの概要
反響・再来訪予測モデルは、DataLakeに蓄積されている「不動産情報サイト アットホーム」のユーザー行動ログを教師データとして、ユーザーがサイトに再来訪するかどうかや、反響があるかどうかを予測します。
先ほどの図に当てはめると、データはユーザー行動ログ、結果は反響の有無と再来訪の有無といえます。ユーザーの来訪回数と使用端末に応じて、以下の12パターンのモデルを作成しています。

予測モデルの作成フロー
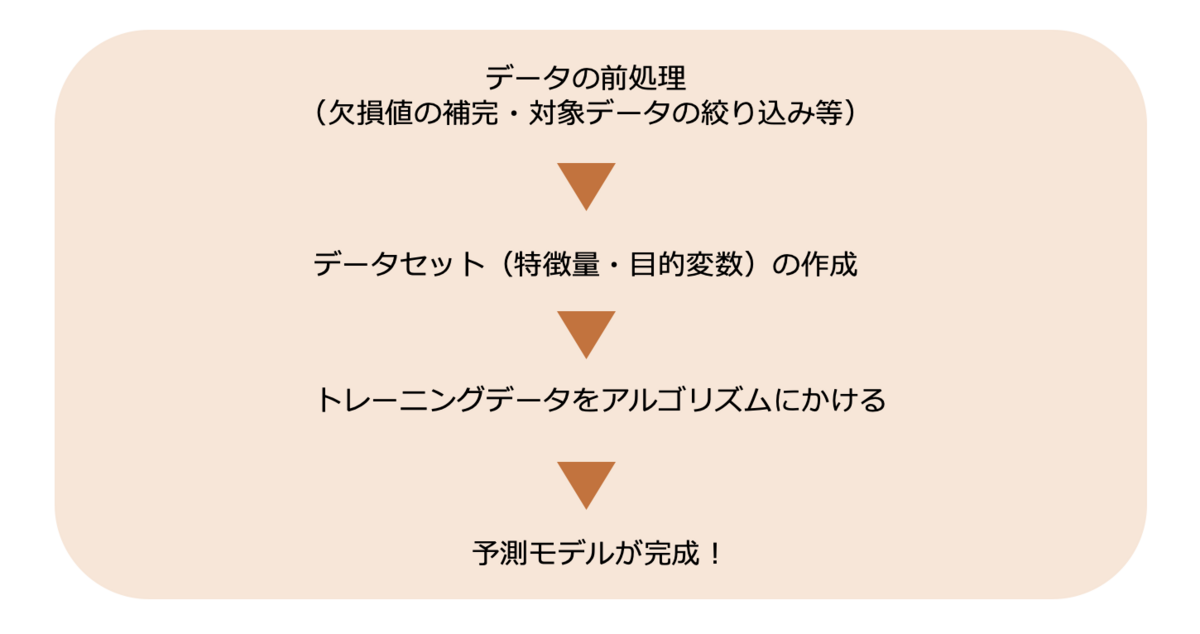
予測モデルの作成フローは冒頭にご説明したとおり、前処理したデータでデータセットを作成して、アルゴリズムにかけるという流れになっています。
それぞれのフェーズでどのようなことを行っているのか、順番に見ていきましょう!
データを前処理する
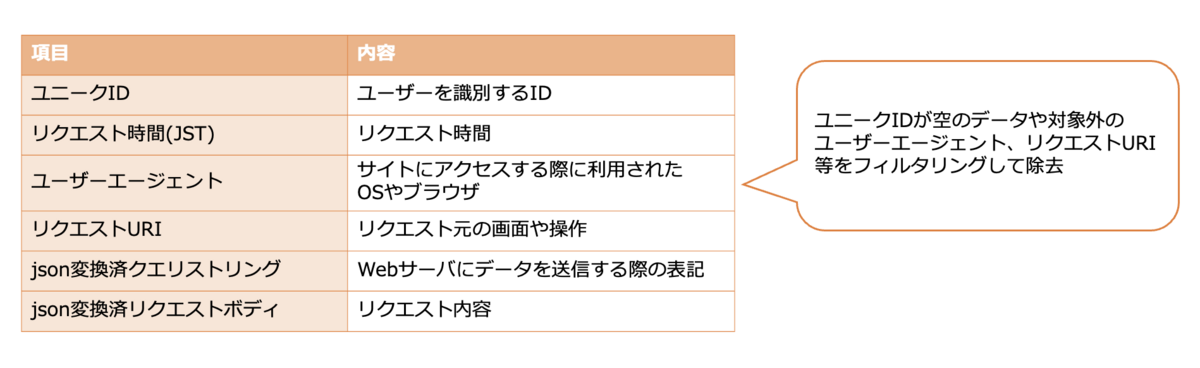
まずは、データの前処理です。
ユーザー行動ログからユニークID、リクエスト時間、ユーザーエージェントといった項目を抽出し、不要なデータをフィルタリングします。
データセットを作成する
次に、前処理をしたユーザー行動ログを使用して、特徴量と目的変数を作成します。
以下の表でお見せしているのは、実際に作成している特徴量と目的変数のほんの一部です。特徴量に関しては、例えば分析する基準日から1日前の総閲覧数、2日前から7日前の間の総閲覧数といったように、抽出期間ごとに計算して項目を作成しています。

作成した特徴量と目的変数は、予測モデルの作成に使用するトレーニングデータと、予測モデルの評価に使用するテストデータに分けておきます。
トレーニングデータをアルゴリズムにかける
最後に、作成したトレーニングデータをアルゴリズムにかけます。
今回使用しているのはXGBoostと生存分析の2種類です。複数のアルゴリズムを組み合わせることで、予測結果の向上や安定化が見込めます。
XGBoost(勾配ブースティング回帰木)
複数の学習器を用いて予測の精度を上げるアンサンブル学習を代表するアルゴリズムのひとつ。
ブースティング※1と決定木※2の組み合わせで構成されている。
生存分析
イベントが発生するまでの時間の長さに対する分析手法。
今回の場合は、「ユーザー単位」や「ユーザー × 物件単位」で「Xな状態のサンプルが、Y日以内に(次の)反響が発生する割合はZ%です」という指標を分析している。Y日後までのアクセスが存在しないユーザーは、観測不可データとして取り除かれる。
※1 ブースティング:1つのアルゴリズムで学習したAI(学習器)を直列に組み合わせ、1つ前の学習器の誤りを次の学習器が修正するという操作を繰り返し行うことで、性能を向上させる手法。
※2 決定木:樹形図によってデータを分析する手法。
これで、予測モデルがひとまず完成しました!
実際に予測モデルを使用するには、まだまだ調整が必要になります・・・
反響・再来訪予測モデルの評価と活用
予測モデルの評価
こうしてできあがった予測モデルを、テストデータを用いて性能評価します。
今回は、以下の適合率と再現率という指標を使用しています。
適合率
予測モデルが陽性(反響する・再来訪する)と予測したサンプルのうち、実際に正解した(反響した・再来訪した)サンプルの割合。
適合率が高いほど、反響・再来訪すると予測したユーザーは高確率で実際に反響・再来訪する。
再現率
実際に正解したサンプルのうち、陽性と予測されていたサンプルの割合。
再現率が高いほど、 反響・再来訪するユーザーを逃さず網羅的に予測できる。
これらは、どちらかを高めるとどちらかが低下するトレードオフの関係にあるため、使用目的に合った適切なバランスになるように、再び予測モデルを訓練していくことが重要です。
予測モデルの活用
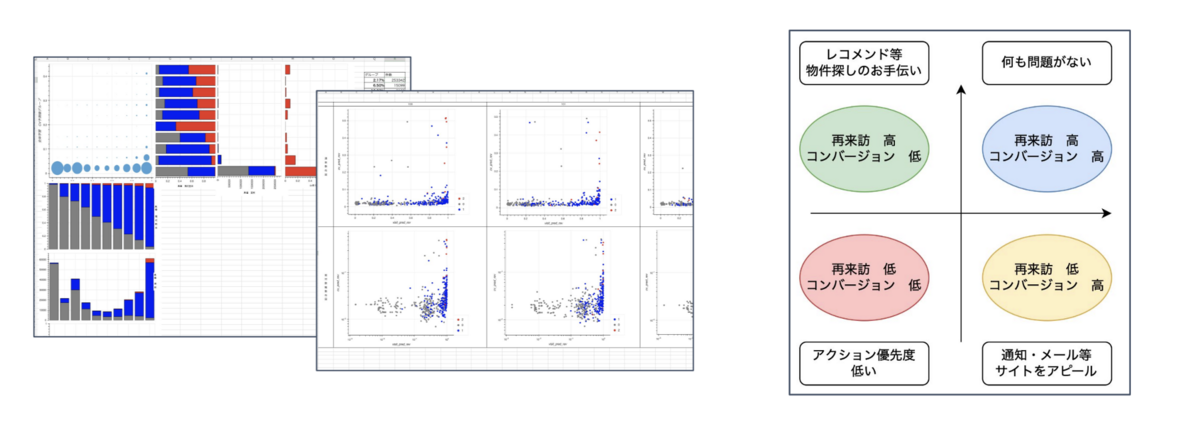
最後に、反響・再来訪予測モデルの活用についてです。
まだ小規模なデータでしか予測モデルを作成していないので、実際に活用するまでには至っていませんが、例えば、予測モデルの結果を散布図やバブルチャートなどのグラフで表すことで、ユーザーをカテゴライズしてターゲットごとに効果的な広告やサービス、レコメンドを提供することが期待できます。
反響・再来訪予測モデルの使い道は、これからさらに検討していく予定です。
今後の開発予定
以上が、反響・再来訪予測モデルのご紹介でした!
今後は、データを大規模化したうえでモデルを再作成し、実際に使用できるように性能を向上させていく予定です。
おわりに
私は、PythonによるコーディングやAWSの知識がほとんどない状態からのスタートだったので、ここまで苦労の連続でした・・・
ですが、その分多くの知識や経験を得られたと思います。
特に、予測モデルの実装で使用したAmazon SageMakerやAWS GlueなどのAWSリソースは、アットホーム社内でもあまり使用されていなかったため、協力会社さんのお力を借りながら少しずつ理解を深めていきました。
まだまだコーディングスキルも予測モデルに対する知識も発展途上ですが、まわりの力を借りながら着実に成長していきたいと思います!
最後まで読んでいただき、ありがとうございました!